The State of the Art for IoT

This article expands on my talk Reactive Systems: The State of the Art for IoT from Reactive Summit 2020.
The term “Internet of Things” was coined by Kevin Ashton in 1999. After a lot of hype, we are finally seeing it come to fruition, in part due to advances in cloud and edge computing.
The principles of Reactive Systems really shine when applied to the Internet of Things (IoT). I worked for over a decade in the somewhat related field of industrial automation. We naturally converged on many of the same patterns, but in a largely pragmatic way. When I discovered the Reactive Manifesto and toolkits, like Akka, that formalised and extended these principles and patterns, I was excited to use these superior technologies, combined with cloud computing and IoT, to solve problems related to renewable energy.
I will describe why I think Reactive Systems are such a natural fit for IoT. Then I will enumerate the elements that define a state-of-the-art IoT platform. I will conclude with speculation on where I think cloud and edge computing platforms for IoT are heading in the near future.
What is IoT?
Just because a device is connected to the Internet does not make it IoT. First of all, IoT must serve a useful function. Second, if the device or information is exclusive to a single person or organization, this is more machine-to-machine automation rather than IoT. IoT must promise a level of interoperability, creating an ecosystem of interconnected devices and systems. To define IoT, I like the framework presented in the book, “The Technical Foundations of IoT”, by Adryan, Obermaier, and Fremantle.
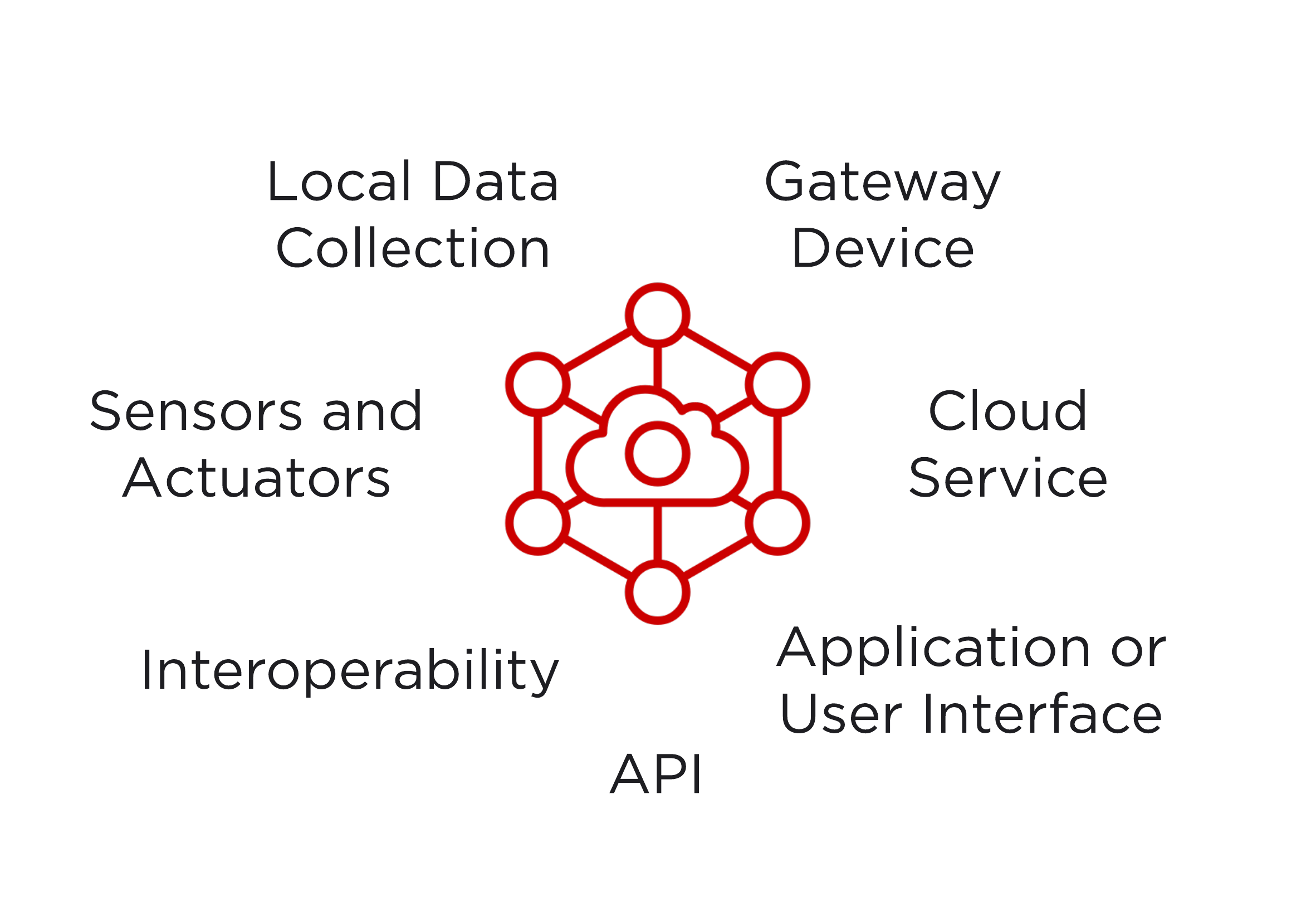
IoT must involve some form of sensing, control, and actuation. IoT must include local data collection—and, I would add, the ability to operate autonomously. The device must be connected to the Internet—hence, the Internet of Things—either directly or through a gateway device, and the Internet must enable novel services that would be impossible if the device was not connected to the Internet. IoT must serve a useful function, either through a user interface, an application, or a service—in other words, data collection alone is not IoT—and there must be an application programming interface (API) for building interactive applications.
Most importantly, IoT interoperates among systems. Too often, IoT becomes synonymous with remote control and nothing more. Furthermore, the fact that your refrigerator can display the weather cannot be considered interoperability. Interoperability must be among a collaborating set of IoT devices, perhaps a diverse set of devices in your home, or between IoT devices and complex systems for energy distribution, agriculture, manufacturing, and transportation. Interoperability is often through software integrations, as the model in the book emphasises, but IoT can also interoperate through markets, price signals, or even through devices independently sensing and maintaining the frequency of the alternating current on the power grid at 50 or 60 Hz.
Reactive Systems for IoT
The principles of Reactive Systems define the state-of-the-art programming models for IoT. Because IoT devices are sensing and actuating physical systems, many of which are critical infrastructure for energy, food, healthcare, and transportation, it is important that they stay responsive, and operate safely and securely. IoT devices communicate over diverse networks, sometimes in harsh and uncertain environments, and some devices even change location. Software systems must embrace the inevitable failures, everything from a single message being delayed, to the temporary loss of communication, to the decommissioning or catastrophic loss of a device.
It is important that IoT systems represent this uncertainty in the data model, in the business logic, and even, intelligently, in the customer experience, rather than trying escape or hide the reality.[1] Most often, only the consumer of the information can interpret the uncertainty with sufficient context. With the inevitable intermittency of communication, IoT devices, as well as the cloud software services that model them, must be able to operate autonomously, in some form or another, exclusively from their local context.
A natural fit for IoT are programming models where entities, like individual IoT devices, can be represented by actors and the run-time handles scaling the number of entities to millions. Erlang OTP, Akka, and Microsoft Orleans have been the preeminent examples. Because these programming models focus on isolation, distribution, location transparency, immutability, asynchronous message passing, and modelling failure, they are a natural extension of the Reactive Systems principles.
It would be difficult for me to concisely demonstrate all of these principles and patterns applied to IoT. They are also easier to communicate with the aid of visualizations. I encourage you to watch my talk, with my friend and colleague Percy Link, on aggregating, optimizing, and controlling thousands of batteries to create virtual power plants for peak shaving and energy-market participation. This presentation demonstrates many of the principles of Reactive Systems through an exemplary and revolutionary IoT system.
IoT Platforms
If you consider the IoT platform in the presentation above and compare it with the IoT platforms from Microsoft Azure, Amazon AWS, and Google Cloud, common abstractions emerge that define the state of the art.
First, a distributed journal for events: immutable facts like telemetry from an IoT device, or systemic events like a new device registration, or a device connecting or disconnecting from the cloud. The distributed journal decouples the producers of messages from the consumers of messages, in both space and time, and allows these events to be reliably shared among many different services. To provide loose coupling among services, and to deliver the right messages to the right services, all of these platforms are capable of flexible message-routing and publish-subscribe messaging for low-latency command and control of IoT devices.
Many IoT applications require the analysis of telemetry over time. For example, analysing a temperature, a pressure, power output, or a binary alert, over minutes, days, or years. Because time-series query and aggregation is so important, all of these platforms have a database optimised for time-indexed queries.[2] Databases that describe rich relationships among IoT devices, however, are equally important for building applications. These relationships can include the properties of a device, where it is currently located in the world, relationships to nearby devices, or even complex hierarchical or proximal relationships of interconnected devices. An important aspect to capture is how these relationships change over time, because if you want to look at a device or its relationships historically, it is important to capture the relationships that existed at the time.
All of these platforms have services or programming models for stream processing. This allows one to build responsive applications that react to events as they happen. But as central as stream-processing is to IoT applications, all of these platforms also have data lakes and platforms for batch processing.[3]
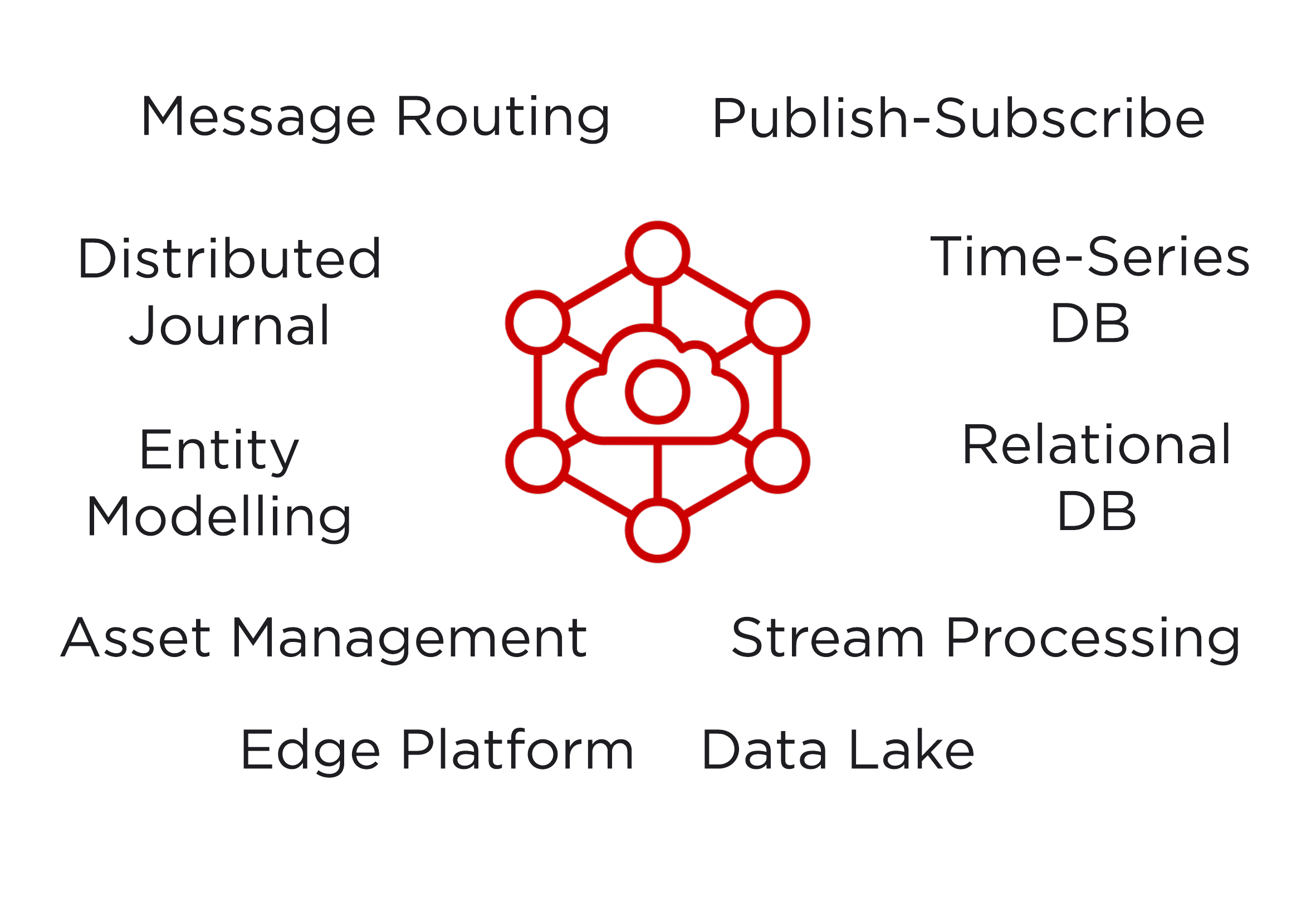
In IoT, the relationship between the device and the cloud is critically important. These platforms all have edge computing components and the more the edge can be treated as an extension of the platform, rather than just a simple interface to the cloud for data collection and control, the more advantageous this is for building sophisticated IoT applications. For example, some of these platforms have the ability to flexibly move streaming computations from the cloud to the edge, or support interfaces for file IO that are the same at the edge as they are for object storage in the cloud. Some platforms are also manufacturing hardware that has hardware root-of-trust and attestation with cloud services. Edge computing for IoT is an active area of development and is ripe for disruption.[4]
In my opinion, asset management is the hardest problem in IoT. Many people say security is the hardest problem, but you can't even begin to secure the IoT if you don't know what you have running. Managing assets is difficult because they change over time as parts are replaced or the asset owner changes. Assets can move and change their relationships to nearby devices over time. As hardware or firmware evolves, device capabilities in a large fleet of devices will be non-uniform. IoT platforms must tackle asset management as a foundational problem and all of these platforms have facilities for managing the provisioning of devices and services, public key infrastructure (PKI), software and firmware updates, and desired-state configuration of devices, at huge scale.
Lastly, all of these platforms have some facility to model individual, stateful entities, like an IoT device. This can simplify the problem of modelling entities, since the software developer can focus on modelling a single entity, relying on the platform to scale the entities to represent millions of IoT devices. When the entity can also represent the state of a physical device or process, it avoids the oversimplification of only representing state in database tables. The ability to model entities in this manner is essential for building reactive and responsive IoT applications, like the ones for bidding distributed energy resources into energy markets, that go way beyond applications for simple data collection, query, and visualization.
The Future for IoT Platforms
I will conclude by describing where I think platforms for IoT are heading in the near future. There is a lot of interesting academic research, but I will focus on trends that are already emerging within the industry.
Undoubtedly, the future is serverless. The future will look a lot like programming with Akka, Erlang OTP, or Microsoft Orleans, where the developer programs entities and relationships that then run on an abstract substrate of compute. The developer will not worry about the infrastructure itself. Kubernetes is great, but it is still largely orchestrating boxes of software—resources, containers, or servers. Kubernetes is a way to move traditional applications to a more flexible computing environment, but I see it as a temporary stop along the way to pure-serverless platforms, where we don't have to run or maintain the infrastructure, and we can orchestrate smaller units of software, as small as a digital-twin representing an individual IoT device.
Serverless programming models for handling state will continue to improve and become the norm. There are a few recent innovations in stateful serverless that have caught my attention:
- Cloudstate is a general-purpose, language-independent serverless platform for modelling stateful entities through event sourcing that relies on Akka Persistence for its implementation.
- Flink Stateful Functions incorporates stateful entities with streaming data. The article Monitoring and Controlling Networks of IoT Devices with Flink Stateful Functions is inspired by the virtual power plant in my presentation above and details a similar challenge of hierarchical, real-time monitoring of assets in a data centre. It is interesting to contrast with the actor-based approach.
- Last year, I hosted the Microservices Patterns and Practices track at QCon San Francisco. In an excellent talk, Chris Gillum explored Stateful Programming Models in Serverless Functions and described Azure Durable Functions, which can be used to model stateful entities with an actor-like, event-sourcing model, in addition to stateful workflows.[5]
- Finally, Cloudflare released a beta for Durable Objects, an actor-like programming model that provides isolation, durability, and addressability, no matter where the object is running.
Modelling individual, stateful entities, like devices, transactions, and customers, will be a first-class part of the platform. The programmer will simply model an individual entity, allowing the platform to handle distribution, failure, and scaling to millions. It may also foster the evolution of different hardware architectures, ones that are not so focused on traditional boxes of software, like virtual machines and containers, but rather ones focused on executing distributed, autonomous entities, like actors.
Streams will emerge as the way to compose entities and workflows, as well as control the dynamics of their execution. Streams can be used to manage concurrency, control timing, provide bounded resource-constraints, and control dynamics by negotiating the rate of consumption.[6] One of the real challenges of serverless functions is making sense of an application composed of many dependent functions. I think the stream will become the new call stack in a distributed, serverless world.
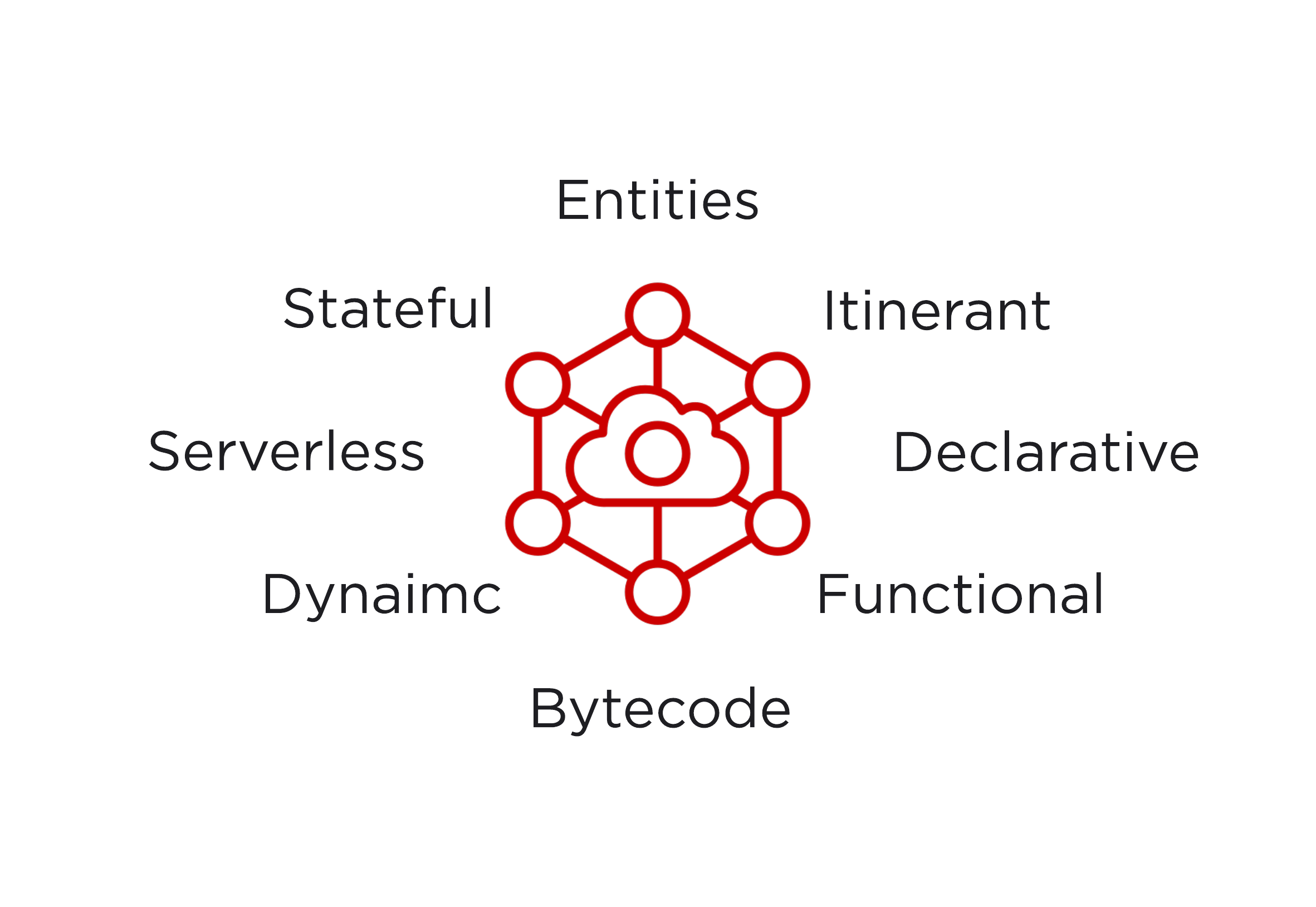
Computation will become more itinerant: it will be able to move from place to place, for example, from the cloud to the edge, or from a batch context to a streaming context. To make this happen, we can't imperatively tell the computing platform what to do. We will need declarative programming models. Think SQL: for the most part, we don't tell the database how to execute the query, we just describe the information we want returned. Functional programming, with its distinct advantages for composition, will be the natural way to express declarative programs.
Platforms for functions-as-a-service (FaaS) only support specific languages, and for some languages, the function is deployed as an executable compiled for a specific platform. There is a huge opportunity to define an execution platform for serverless computing where instead we deploy bytecode for functions or entities. This would support the itinerant model, allowing computation to move from the cloud to the edge, or even from one architecture to another. I envision this as a .NET-like platform for serverless computing with an ecosystem of programming languages and exceptional tooling. This is one of the reasons there is a lot of interest in WebAssembly for IoT applications.
Finally, I believe the operators of the IoT platforms will develop empirical approaches to improving cost, latency, locality, throughput, and the like. For example, a recent paper from Microsoft Research detailed an empirical, longitudinal study to optimise FaaS execution on Microsoft Azure, including the use of autoregressive integrated moving average (ARIMA) models to improve FaaS cold-starts. I believe the operation of the platform itself will look more and more like traditional process engineering to manage dynamics, state, performance, and operational objectives. For example, if the platform provider has your bytecode, it could run experiments in different configurations, with different run-time optimisations, and even execute on different architectures, and decide which one is the most effective, borrowing approaches for continuous improvement, like Design of Experiments, from the process industries.[7]
Conclusion
It is difficult to predict the many applications of IoT once it has reached the stage of ubiquitous expansion.
— “The Technical Foundations of IoT”, Adryan, Obermaier, and Fremantle
The IoT will be successful when it melts into the background and we don't even notice the novelty of something connected to the Internet, interoperating with other devices, services, and systems. Some products are starting to achieve this, while others have a long way to go. The evolution of serverless computing platforms, combined with the principles and patterns of Reactive Systems, will play an important role in making the IoT successful.
For example, consider an IoT device that is offline and has not reported telemetry for some time. It would be misleading to extrapolate from the last-known value on a time-series graph without some visual indication. As another example, for a payments system that is eventually consistent, like payments for electric vehicle charging, it is important to deliver a customer experience that is consistent with this fact, perhaps displaying the bill to the customer, but indicating that the final payment is still pending. ↩︎
I worked for many years on the leading time-series database for industrial automation. It always amazed me that a great open-source time-series database never emerged, especially one focused on long-term retention, industrial automation, and IoT. The solutions that did exist were too influenced by short-term metrics retention for application monitoring. We have seen this trend change in the past few years with open source databases that are finally suited for IoT, but I expect continuing innovation to provide platforms for time-series storage, analysis, and query, rather than just individual databases. We are seeing some of this innovation with Influx Cloud, Azure Time Series Insights, and AWS Timestream. It is so interesting for me to watch all of these time-series databases and platforms learn the same fundamental lessons of time-series data collection, processing, storage, and query that we learned 20 years ago. Perhaps a blog post for another day. ↩︎
A few years ago, there was some notion that the so-called Lambda Architecture, where platforms run parallel batch and stream-processing systems, was falling out of favour, but I think it is alive and well. There are definitely challenges and trade-offs in maintaining parallel batch and streaming architectures (e.g., keeping code and business logic consistent between the two), however, some applications run much better in a streaming context, whereas some questions can only be answered in a batch context. ↩︎
Disruptions I anticipate: embracing Reactive Systems principles at the edge, an increase in the popularity of edge-twins and conflict-free replicated data types (CRDTs) at the edge, and superior programming models for firmware. ↩︎
There is an increasing focus on stateful entities, but stateful workflows are just as important. Many operations, like the provisioning of an IoT device, are complex and composed of multiple, dependent steps, some of which can take a long time to execute, but must be stateful in their overall execution. ↩︎
Streams might be expressed in a data-flow programming model, like Akka Streams, or in Scala-like for-comprehensions. For a flavour of how streams change the programming model, see my series of rethinking streaming workloads. ↩︎
I explored this topic in my article Observations on Observability. ↩︎