From a Time-Series Database to a Key Operational Technology for the Enterprise: Part III

This three-part series expands on a talk that I gave at a conference focused on time-series data in 2018.
This three-part series is focused on the challenges of elevating a time-series database from being just an IT application, used in the data center, to a critical operational technology, used throughout the entire enterprise, in support of real-time decision making. The first article in the series explored some challenges related to time and highlighted the complexities of the data ingestion pipeline. The second article described the importance of integrating time-series data with asset metadata and asset models, in order to provide context to the underlying telemetry. In this article, the third and final article in the series, I will examine how to integrate a time-series database with the many systems that surround it, and I will focus on how to achieve these integrations in a reliable and scalable manner.
Integrations
In the second part of this series, I described how incorporating asset metadata and asset models is essential for providing context for time-series data. The asset metadata, along with the models describing the relationships between and among assets, do not usually reside in one system. The information required to get a complete picture of an asset is, most often, scattered across many disparate systems—Customer Relationship Management (CRM), Enterprise Resource Planning (ERP), Manufacturing Execution Systems (MES), Supervisor Control and Data Acquisition (SCADA), among many, many more.
To provide context, the telemetry stored in the time-series database needs to be represented in terms of asset models defined in these other systems, but how can we integrate asset data and time-series data when they live in different systems? As I detailed in the second part of this series, not all asset information is available when time-series data are ingested, and with the need for asset models that are more complex than simply tagging telemetry on ingress, we must have ways to integrate time-series data with the many enterprise systems that are the systems-of-record for asset information. Often, these other systems are not well-positioned to operate at an enterprise scale, either because they are legacy systems—applications that cannot support a large number of queries, or only support interfaces or protocols that fail to integrate well with modern platforms—or because they reside in an isolated security context, like a control system, in which they cannot be exposed broadly to other systems in the enterprise.
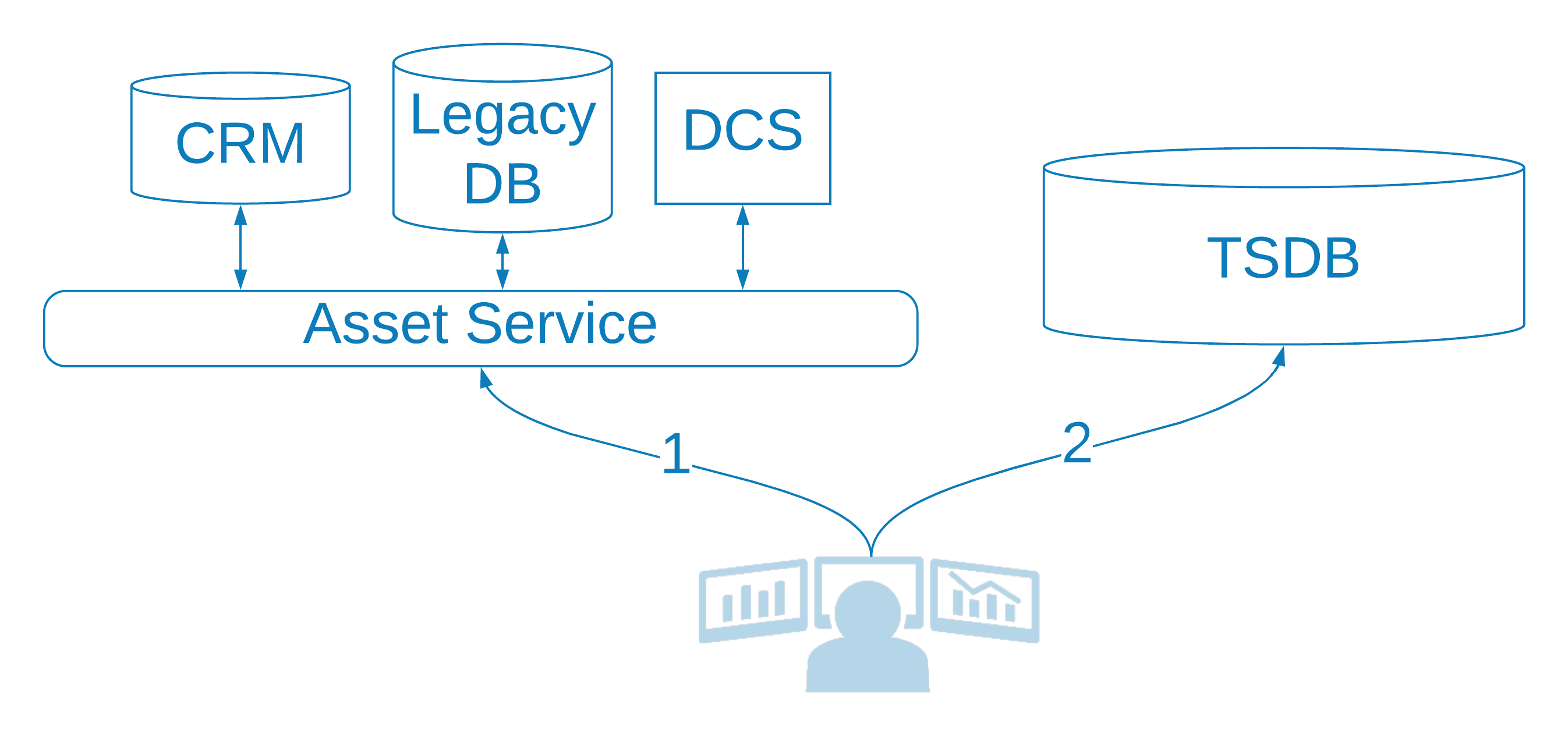
To incorporate time-series data at the enterprise level, it is almost always necessary to integrate and expose the asset metadata and models from these other systems in some form of asset service. This asset service may just be a gateway, abstracting and providing a common interface to these distinct systems, but, given that some of these systems are not built to meet the demands of an enterprise-level application, the asset service usually ends up having its own databases and caches. Asset information from the other business systems is usually synchronized on a periodic basis (e.g., daily), unless the other systems support mechanisms for more real-time synchronization (e.g., via publish-subscribe). To address security concerns, it is also common for the asset service to enforce a unified, role-based access-model across the data from these disparate systems.
Applications leverage the asset service to navigate the asset models, discover asset metadata, and resolve the underlying assets to a set of unique and stable identifiers—a device identifier, a serial number, an address, an arbitrarily assigned UUID—that can be used to query the time-series database for the associated telemetry. Often, these stable and unique identifiers are the only asset metadata available when the time-series data are ingested. This indirection provides a loose coupling that allows asset metadata and models to be applied, and even modified, after the telemetry has been stored in the time-series database. The asset model is also convenient in that people usually do not want to be concerned with these identifiers, preferring to refer to the assets by name, address, location, customer, and so on. The integration between the time-series database and the asset service might be done directly by the client, or it may be abstracted and unified through a broader time-series service.
With the rise in popularity of time-series systems, there has been a lot of innovation in stream-processing services, like Apache Spark, Apache Flink, Google Cloud Data Flow, and the like. If you are unfamiliar with the problems that these systems solve, or the challenges of building and operating them, see the comprehensive tour of modern data-processing concepts by Tyler Akidau. Time-series databases and stream-processing platforms certainly have an affinity, given that they both focus on the processing of unbounded streams of data, in near real-time. I believe it is important for a time-series database to have some basic, low-friction stream-processing facilities, even if they are limited to filtering or roll-ups on a single stream. It is unlikely, however, that a time-series database can, or should, try and compete with the richness of the programming and execution models of a stream-processing platform. Time-series databases and stream-processing platforms should stick to their strengths, but they also need to integrate effectively with each other. We often want time series and asset data to be leveraged as inputs to stream-processing systems and, conversely, we often want time-series data recorded as the outputs of streaming analytics, for historical representation and analysis.
Throughout this series, I have discussed integrating the time-series platform with the many other systems that surround it—collecting data from sensors, control systems, and services; the complexities and dynamics of a flexible and durable ingestion pipeline; referencing asset metadata and asset models stored in a diverse collection of enterprise systems; and interfacing with stream-processing platforms. For the remainder of this article, I will explore how to integrate all of these systems effectively, since this is critically important. If we are going to use a time-series platform as an operational technology for which to operate our business, it must be reliable, it must be robust, and it must be scalable.
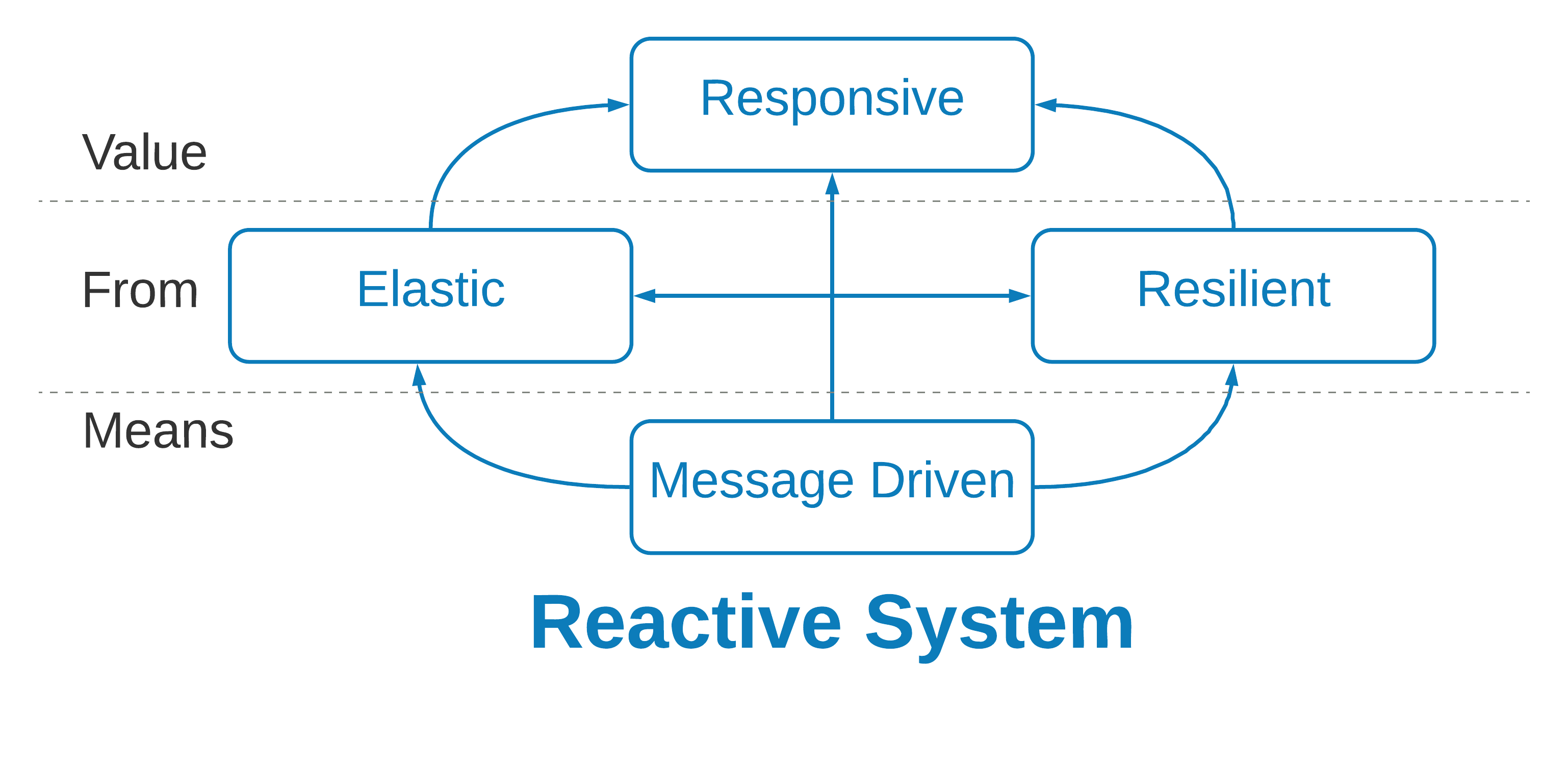
The Reactive Manifesto, originally authored by Jonas Bonér, Dave Farley, Roland Kuhn, and Martin Thompson in 2013, is a set of design principles for architecting systems. Embracing events (which are either commands, or immutable facts from the past) and communicating asynchronously via messages, supports building systems that are responsive, resilient (responsive under failure), and elastic (responsive under load). Constructing time-series systems in this manner is extremely natural, since times-series samples are inherently immutable observations from the past, communicated via messages. The fact that time series are generally unbounded, combined with the demands for near real-time data, leads us to naturally embrace patterns that work with the eventually-consistent and loosely-coupled nature of these systems.
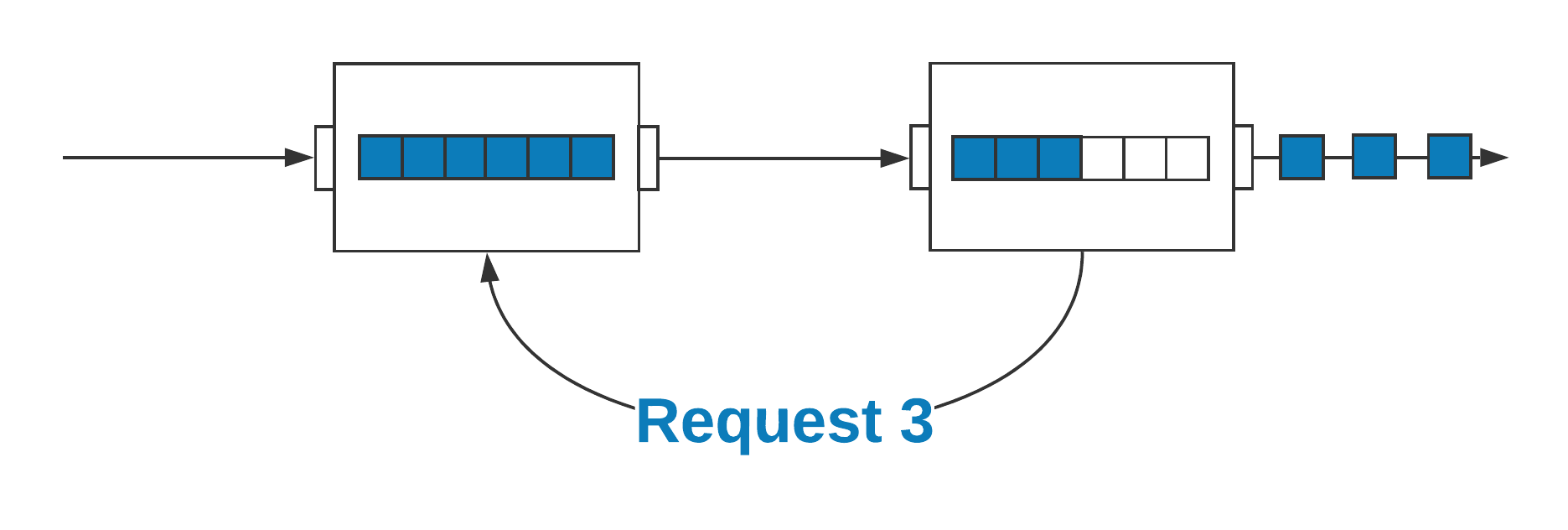
Unbounded series can present a problem, in that messages can be produced faster than the downstream resources can process them. This can be a transient or a permanent dynamic. The problem is exacerbated by the typically huge volumes of time-series data, from many sources, as well as the many buffers of messages throughout the ingestion pipeline, meaning we can consume large numbers of messages in a very short period of time, like processing a backlog in a durable message-queue following a downstream failure. Reactive Streams, an initiative that grew out of the Reactive Manifesto as a collaboration by engineers from Lightbend, Pivotal, Netflix, Red Hat, Oracle, Twitter, and others, addresses this problem. Many time-series and stream-processing systems work around this problem by polling or blocking, if they consider it at all. Reactive Streams, on the other hand, is a set of interfaces and protocols that provide a standard for efficient stream-processing and interoperability, through non-blocking back-pressure.
In Reactive Streams, rather than having the producer of a message push the message to the consumer without any feedback, the consumer signals demand to the producer and pulls messages. This signalling can be performed asynchronously, and it can be batched, in order to amortize the cost of the message passing, making it efficient.
Somewhat misunderstood, the Reactive Streams protocol itself is not meant for application developers—it is meant to be used by library developers, as a means of interfacing components in a reliable way, through bounded resource constraints. In general, application developers should not have to worry about the Reactive Streams semantics, embracing Reactive Streams through a higher-level, end-user API. One of these APIs is the Akka Streams API. I have published an article with a motivating example for using the Akka Streams API, as well as an article demonstrating how it handles common patterns encountered when streaming time-series data.
Unfortunately, despite the Reactive Streams initiative being around for about five years now, it has not been adopted as widely as it should be. Many systems suffer from the lack of back-pressure and the reliability and resource constraints that it provides. Reactive Streams was recently included in Java 9, but its popularity in languages outside of the JVM remains too limited. As the popularity and importance of time-series and stream-processing systems continues to grow for providing operational intelligence to the enterprise, we must construct these systems with the reliability that the business demands. I believe Reactive Streams is something that should be embraced much more broadly.
Summing up, there are many systems-of-record for asset information. Time-series data must be integrated with these systems to provide the necessary context, through asset models and asset information. Time-series-data platforms have a strong affinity with stream-processing platforms and publish-subscribe messaging. In order to integrate all of these systems reliably and meet the demands of an operational setting, embrace the ideas of the Reactive Manifesto and implement systems using the Reactive Streams protocol.
Takeaways
In this three-part series, I detailed some of the challenges of taking a time-series database from being just another data-store used in IT, and elevating it to be a key operational technology used by the entire enterprise. I noted that time is multifaceted. In addition to the time that data are sampled, we must consider ingestion latencies, the possibility of modifying or deleting samples, or, to provide additional context, time-frames. In an operational setting, the time-series ingestion pipeline requires a lot of investments in terms of reliability, durability, flexibility, and scalability. It also requires mechanisms to provide visibility into behaviours or dynamics of interest.
To contextualize times-series data in the language of the business, we need to represent the underlying telemetry through the lens of asset metadata and asset models. The asset metadata and asset models will change over time and come from many different systems-of-record. Assets themselves will also change over time. This means that we must integrate the time-series database with many other systems—disparate sources of time-series data, enterprise systems for asset metadata and models, publish-subscribe systems for sharing data, and stream-processing platforms for data analysis and transformation. To build time-series platforms with the reliability and scalability that the business demands, we should embrace the ideas of Reactive Systems and use Reactive Streams for interfacing systems.
A time-series platform is uniquely positioned to support so many different aspects of the business. It can be used to drive customer-facing applications and services; it can be used internally, for operations, maintenance, support, and product improvement; and it can be used to unify many disparate systems, providing a common platform for collaboration, analysis and real-time decision making. I cannot recall how many times I have seen an enterprise tie together disparate systems—sensors, control systems, business systems, legacy systems, stream-processing systems—surfacing information that was not available before, or not available in near real-time, so that people can take action. This always leads to unexpected insights that were just not possible before. It empowers people. If you can put the right information, in front of the right people, at the right time, great things are possible.