Partitioning Akka Streams for Scalability and High-Availability
I expand on these concepts in my Scale by the Bay presentation.
In an earlier article, I detailed a number of techniques that can be used to maximize the throughput for individual Akka Streams. In a subsequent article, I also explored how an Akka Stream can be internally partitioned, in order to improve throughput. The techniques presented in these articles primarily involved maximizing concurrency.
After applying these techniques, what if a single Akka Stream remains insufficient for processing a streaming workload? Perhaps there is a continuous stream of data that is just too much for a single stream to process—the stream will have bounded resource-constraints, because Akka Streams have flow control, but it will fall farther and farther behind. Or what if a single stream cannot process the workload with a low enough latency—perhaps the workload is extremely dynamic, with huge bursts of messages interspersed with periods of relatively few messages?
Partitioning a stream externally can be an essential technique for maximizing the overall scalability and aggregate throughput of a streaming workload. Even if throughput is not a primary concern, external partitioning may be crucial if the workload is resource constrained—for example, an application that processes very large files, or has a large in-memory cache, and exceeds the IO, CPU, or memory resources of a single server. Just as important, external partitioning can be critical for fault-tolerance and high-availability—for example, running a set of streaming workloads, where any individual stream can be stopped, restarted, or failed, without affecting the overall throughput or availability of the service-as-a-whole.
In this article, I will explore some techniques for externally partitioning Akka Streams, both statically and dynamically, to provide scalability and high-availability.
Static, External Partitioning
If a stream can be partitioned externally—meaning that multiple, independent streams can be executed in parallel, with each stream handling a subset of the aggregate stream—the streaming workload can be scaled, essentially linearly, just by adding additional streams. This approach is straightforward and reliable, and it can achieve massive scalability.
Partitioning streams externally also affords a lot of flexibility. The stream processing each partition can be executed within the same program—perhaps with an actor managing the life-cycle of each stream—or on different servers, or even in different data centers, depending on the scalability and availability requirements of the service.
As an example, consider an industrial setting, where there are thousands of devices controlled by software. Imagine each device periodically emits a batch of time-series metrics to a new file in a directory on the local file-system. We want to aggregate the time-series metrics from all of these devices and make them available to other services to support analysis, alerting, and real-time decision making. A process running an Akka Stream can monitor the file-system on each device for new files, reading the files and aggregating the metrics to a central service. In this case, the source of the stream is partitioned per device, with the overall stream being the aggregation of all these individual sources.
To demonstrate, the following stream monitors a specific directory on the local file-system for new files, using the Alpakka DirectoryChangesSource Akka Streams source. When a new file is created, the stream will read each line in the file and publish it to the metrics topic in Apache Kafka, using the Akka Streams Kafka producer, also from the Alpakka project. This example uses a shared Kafka producer, so that the producer is only created one time, rather than being created for each new file. Once the file has been published to Kafka, the file is moved to a backup directory. The retention of files in the backup directory is managed independently.
val directory = Paths.get("/var/log/metrics")
val backup = Paths.get("/var/log/metrics/backup")
val producerSettings = ProducerSettings(system, new ByteArraySerializer, new StringSerializer)
.withBootstrapServers(bootstrapServers)
val kafkaProducer = producerSettings.createKafkaProducer()
val topic = "metrics"
val collectNewFiles = Flow[(Path, DirectoryChange)].collect {
case (path, change) if change == DirectoryChange.Creation => path
}
val writeMetricsToKafka = Flow[Path].mapAsync(1) { path =>
FileIO.fromPath(path)
.via(Framing.delimiter(
delimiter = ByteString(Properties.lineSeparator),
maximumFrameLength = 1024,
allowTruncation = true))
.map(_.utf8String)
.map(new ProducerRecord[Array[Byte], String](topic, _))
.runWith(Producer.plainSink(producerSettings, kafkaProducer))
.flatMap(_ => Future.successful(path))
}
val moveFileToBackupDir = Flow[Path].mapAsync(1) { path =>
Future {
Files.move(path, backup.resolve(path.getFileName))
}
}
DirectoryChangesSource(directory, pollInterval = 1 second, maxBufferSize = 1000)
.via(collectNewFiles)
.via(writeMetricsToKafka)
.via(moveFileToBackupDir)
.log("files-processed").withAttributes(Attributes.logLevels(onElement = Logging.InfoLevel))
.runWith(Sink.ignore)
This Akka Stream can run independently on each device—perhaps on hundreds or thousands of devices—to produce the aggregate Kafka metrics topic. If a new device is commissioned or decommissioned, a new stream starts publishing, or stops publishing, respectively, to the aggregate Kafka topic, without any impact on the streams running independently on the other devices.
Dynamic, External Partitioning
Streams can also be dynamically, externally partitioned, which allows for dynamic scaling as workloads increase or decrease. A prominent example of this partitioning strategy is the Akka Streams Kafka consumer. When using a consumer group, the Kafka brokers will naturally partition the source by distributing the Kafka topic-partitions,[1] uniformly, across the active consumers.
To illustrate, if a Kafka topic has 100 partitions and there are 5 streams consuming from a consumer group for this topic, 20 partitions will be assigned to the source of each stream. If instead, 10 instances of the stream are running for the consumer group, each stream will be assigned just 10 partitions, and this may yield double the throughput.
As a concrete example, consider an application that consumes the aggregate Kafka metrics topic presented in the previous section and writes the samples to a database, to support real-time dashboards, reporting, and analysis. The writeToDatabase flow is left to the imagination of the reader, but it would handle parsing the messages and batching writes to the database, like I detailed in my article that provided a motivating example for using Akka Streams. This stream can be run in parallel, on multiple servers, and the Kafka consumer-group will ensure that the partitions for the topic are evenly distributed among the active consumers.
val topic = "metrics"
val consumerSettings = ConsumerSettings(system, new ByteArrayDeserializer, new StringDeserializer)
.withBootstrapServers(bootstrapServers)
.withGroupId("database-ingress")
.withProperty(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest")
val (consumerControl, consumerDone) = Consumer.committableSource(consumerSettings, Subscriptions.topics(topic))
.via(writeToDatabase)
.map(_.committableOffset)
.groupedWithin(1000, 5 seconds)
.map(group => group.foldLeft(CommittableOffsetBatch.empty) { (batch, elem) => batch.updated(elem) })
.mapAsync(1)(_.commitScaladsl())
.toMat(Sink.ignore)(Keep.both)
.run()
An advantage of this dynamic partition-assignment is that it requires less up-front static configuration or service orchestration, and if the workload is seasonal or dynamic, the stream instances can be scaled up or down to meet the necessary throughput requirements, without adjusting any other configuration. When a new consumer is started or stopped, the Kafka brokers will dynamically reassign the partitions within the consumer group. If there is a burst of messages and the consumers start to exhibit lag, the number of consumers can be scaled up, to improve the overall throughput. This type of partitioning, combined with dynamic scaling, is easy to achieve on many cloud platforms, or container-orchestration platforms, like Kubernetes.
Dynamic partitioning also provides fault-tolerance. In the Kafka example, a set of consumers can be running and if any single consumer fails—maybe due to a server restart or a network partition—the Kafka topic-partitions assigned to the failed consumer will be automatically reassigned to the remaining consumers with minimal disruption to the overall streaming workload.
Partitioning Streams with Actors
Finally, actors can be used to run individual streams and manage their life-cycle. For externally partitioned streams, one actor can be dedicated to managing the life-cycle of each stream. As a result, one process can be responsible for executing many stream partitions. Even more powerful, however, actors can be used to distribute a collection of streaming workloads across an Akka Cluster, using Cluster Sharding, yielding both scalability and fault-tolerance.
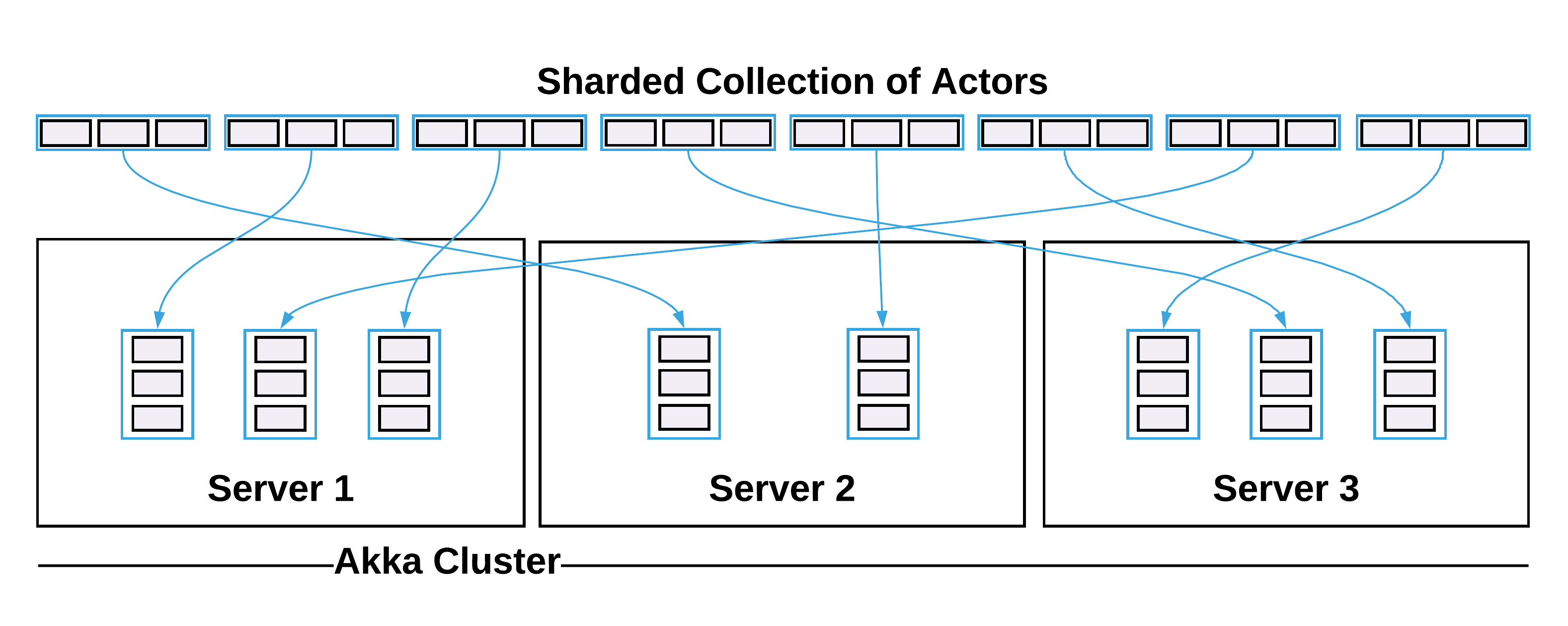
The intricacies of this approach are well beyond the scope of this article. In my series on integrating actors and streams, I detailed how an actor can be used to both manage the life-cycle of a stream and distribute a streaming workload in an Akka Cluster. With this approach, if any individual stream fails, the actor will be responsible for restarting it—perhaps maintaining state as to where it left off, managing side-effects as a result of restarting the stream, or using a back-off supervisor to maintain the integrity of other services—and, if any individual node in the Akka Cluster fails, Akka Cluster Sharding will ensure that the actors managing the individual streams on the failed node are automatically rebalanced and restarted on another node in the cluster. This can be a very effective approach for managing partitioned, streaming workloads in a scalable and highly-available manner.
Summary
The Akka Streams API offers a robust, reliable, expressive, and efficient means for executing streaming workloads. At scale, these workloads can exceed the resource constraints of a single Akka Stream and they need to be scaled horizontally. In this article, I examined techniques for externally partitioning Akka Streams, both statically and dynamically, to meet the overall scalability requirements of a streaming application. In addition, I explored how partitioning streams for scalability is complimentary to ensuring fault-tolerance and high-availability. Combining these techniques with the approaches for maximizing the throughput of individual Akka Streams, described in my previous articles, will allow you to build extremely reliable and enormously scalable systems for streaming workloads. Happy hAkking!
Apache Kafka partitions topics for scalability, not to be confused with the partitioning of Akka Streams themselves, although, the Kafka topic-partitions can be used as a unit for partitioning Akka Streams, either individually, or via the Kafka consumer-group. ↩︎