Partitioning Akka Streams to Maximize Throughput
I expand on these concepts in my Scale by the Bay presentation.
In an earlier article, I detailed a number of techniques that can be used to maximize the throughput for Akka Streams. The article focused on improving the throughput of individual streams and the techniques mainly involved, but were not limited to, maximizing concurrency. A topic that I did not explore in that article was how Akka Streams can be partitioned to improve throughput.
There are many ways to partition an Akka Stream and the ability to partition a stream often depends on how naturally amenable the underlying workload is to partitioning. In this article, I will explore some techniques for partitioning individual Akka Streams to maximize throughput. Similar to the previous article, rather than providing elaborate examples, I will use self-contained samples that are easy to experiment with, in order to compare relative performance.
Broadcast
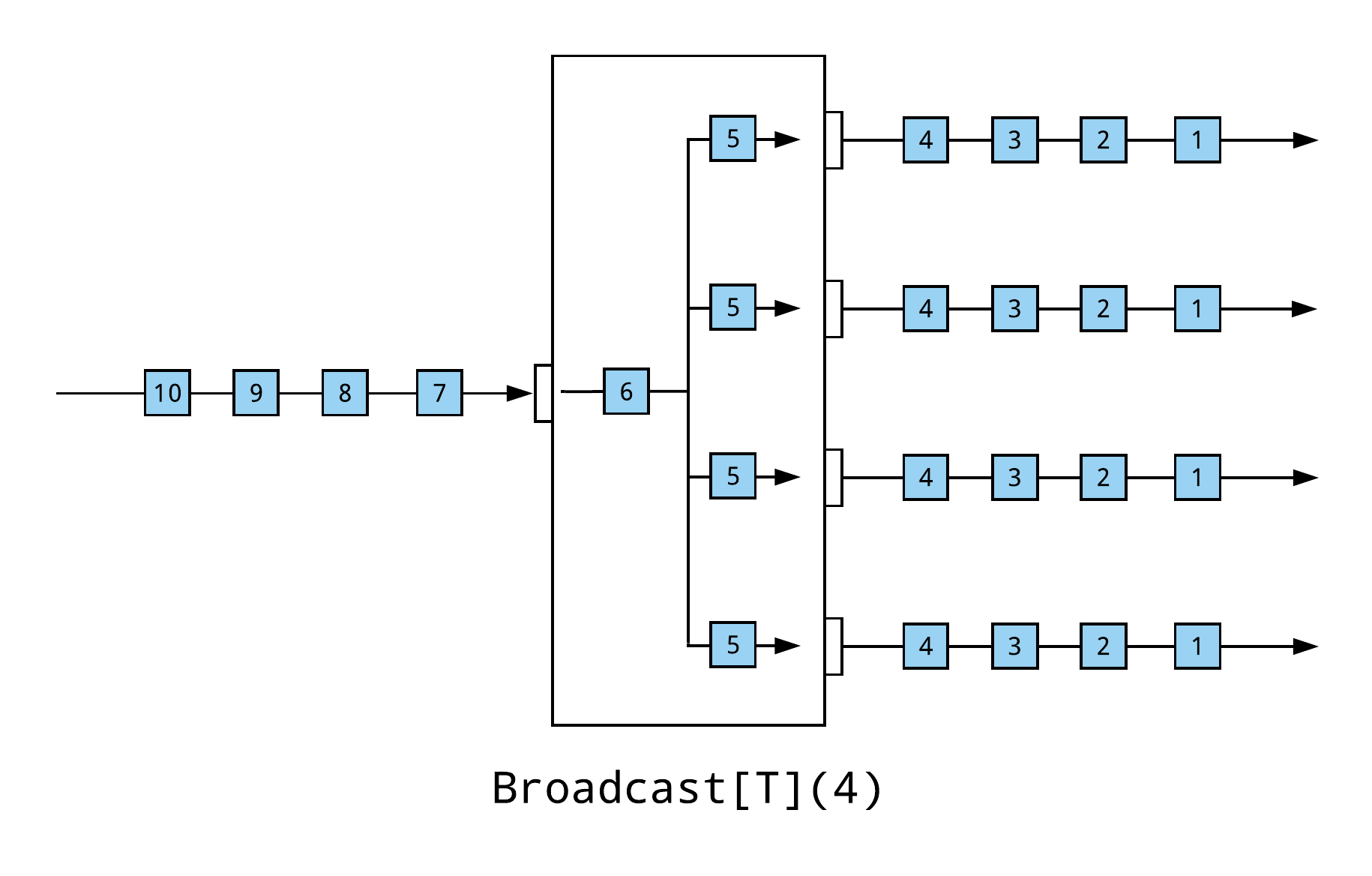
One of the most straightforward ways to partition a stream is to simply broadcast every upstream element to a set of downstream consumers. Every downstream consumer will receive exactly the same stream of messages and can independently apply filtering, transformations, aggregations, or side-effects.
Throughout this article, I am going to use the following function to simulate a CPU-bound workload:
// Simulate a uniform CPU-bound workload
def spin(value: Int): Int = {
val start = System.currentTimeMillis()
while (System.currentTimeMillis() - start < 10) {}
value
}
The following example uses the Broadcast fan-out junction, from the Akka Streams graph DSL, to broadcast every element to a set of four downstream consumers. Each downstream consumer will receive the same elements, in the same order.
val flow = Flow.fromGraph(GraphDSL.create() { implicit b =>
import GraphDSL.Implicits._
val workerCount = 4
val broadcast = b.add(Broadcast[Int](workerCount))
val merge = b.add(Merge[Int](workerCount))
for (_ <- 1 to workerCount) {
broadcast ~> Flow[Int].map(spin) ~> merge
}
FlowShape(broadcast.in, merge.out)
})
Source(1 to 1000)
.via(flow)
.runWith(Sink.ignore)
Broadcasting every element can be effective in situations where the stream cannot be exclusively partitioned. For example, the downstream consumers may need to perform independent, parallel operations on the entire stream. In other scenarios, the consumers may need to consider adjacent elements—elements before or after the current element—and, thus, require a broadcast of the entire stream.
Understanding Concurrency
Interestingly, the example above will execute four-times slower than the following, trivial stream, which executes a workload equivalent to just one of the consumers above.
Source(1 to 1000) .map(spin) .runWith(Sink.ignore)
Why is this? When the entire stream is broadcast to four downstream consumers, it is doing four-times the work, but when a stream is partitioned, are the downstream consumers not executed in parallel? The answer is, no. I explained the reason why in my previous article on maximizing throughput for Akka Streams. By default, Akka Streams use operator fusing and adjacent stream stages are executed by a single underlying actor. In most cases, this is the most efficient way to execute the stream, and it also has attractive properties in terms of efficient garbage-collection. When trying to maximize the throughput of downstream consumers, however, we usually want them to execute in parallel. The only thing that is required to execute the downstream consumers concurrently is the addition of an asynchronous boundary, using async.

In the following example, each stream will run concurrently, with the addition of async, and it will execute four-times faster than the example in the previous section.
val flow = Flow.fromGraph(GraphDSL.create() { implicit b =>
import GraphDSL.Implicits._
val workerCount = 4
val broadcast = b.add(Broadcast[Int](workerCount))
val merge = b.add(Merge[Int](workerCount))
for (_ <- 1 to workerCount) {
broadcast ~> Flow[Int].map(spin).async ~> merge
}
FlowShape(broadcast.in, merge.out)
})
Source(1 to 1000)
.via(flow)
.runWith(Sink.ignore)
For the examples in the remainder of this article, I will always use async to execute the downstream consumers concurrently.
Partition
If a stream can be exclusively partitioned, as is often the case, it can be executed efficiently, by maximizing the parallel processing. In the following example, each downstream consumer processes just one-quarter of the total elements and the stream executes four-times faster than the broadcast example presented in the previous section.
val flow = Flow.fromGraph(GraphDSL.create() { implicit b =>
import GraphDSL.Implicits._
val workerCount = 4
val partition = b.add(Partition[Int](workerCount, _ % workerCount))
val merge = b.add(Merge[Int](workerCount))
for (_ <- 1 to workerCount) {
partition ~> Flow[Int].map(spin).async ~> merge
}
FlowShape(partition.in, merge.out)
})
Source(1 to 1000)
.via(flow)
.runWith(Sink.ignore)
It is very common, and usually sufficient, to exclusively partition a stream based on a unique identifier—like the consistent hash of an address, or a unique customer, session, or device identifier—maintaining total-ordering within each partition, without necessarily maintaining total-ordering for the entire stream.
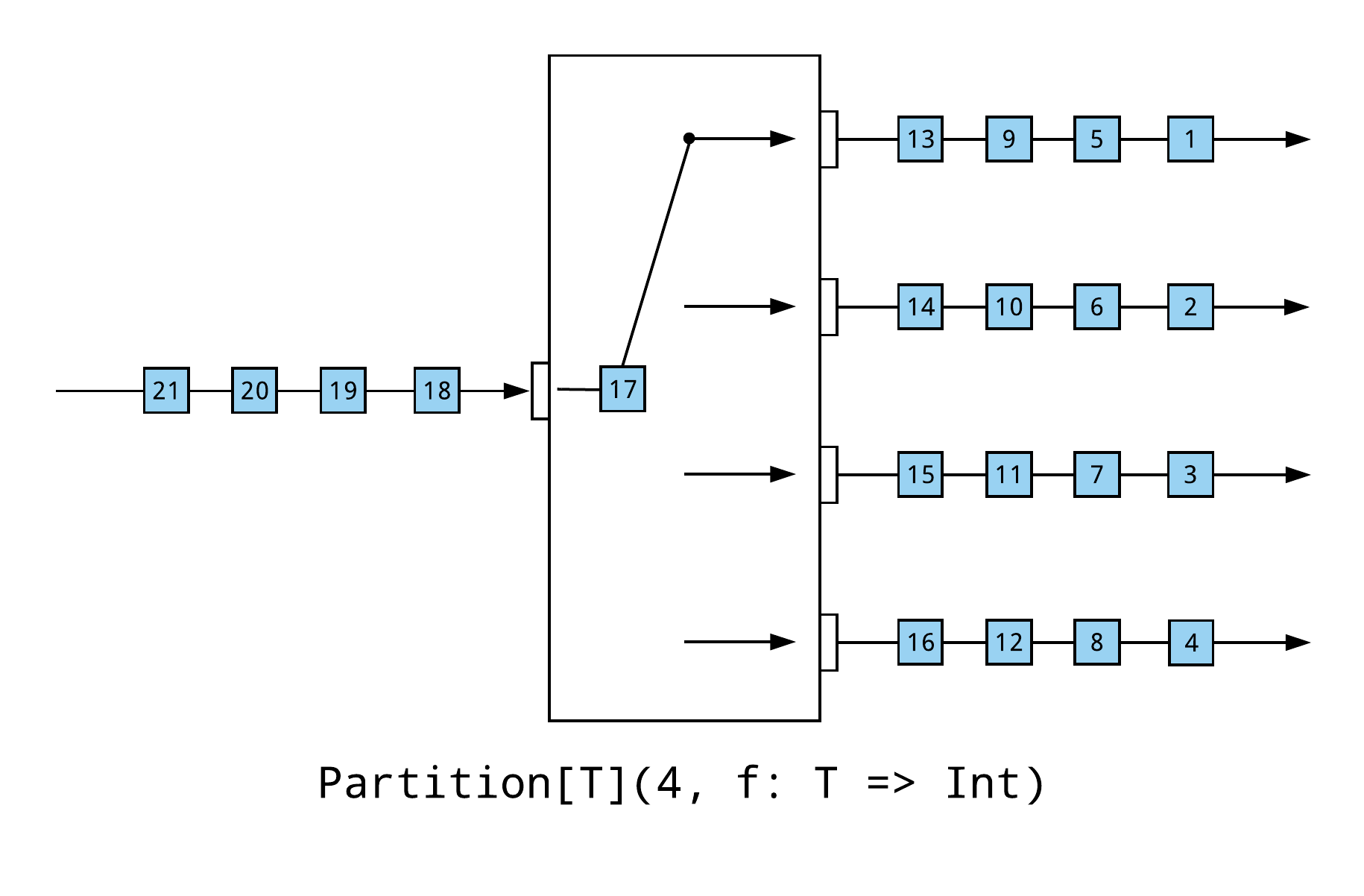
In terms of selecting the number of partitions, for a CPU-bound workload, the number of partitions should be proportional to the number of CPU cores. If the workload is IO bound, like an asynchronous network request to another service, it can be effective to partition the stream well beyond the number of CPU cores. It is also important to consider other workloads that are executed as part of the same stream, or even other workloads within the application. For instance, if there are two stages in the stream that can execute concurrently and you want to maximize the parallelism within each stage, it might be best to partition the stream to saturate half of the cores with the first stage, while saturating the other half with the second stage.
Balance
In situations where downstream workloads are non-uniform and the total order of the stream, or an individual partition, is not required, Balance can be used to saturate downstream consumers.
Consider the following non-uniform workload, where one-quarter of the time it will consume CPU for 100 milliseconds, but the rest of the time, it will only consume CPU for 10 milliseconds.
// Simulate a non-uniform CPU-bound workload
def nonUniformSpin(value: Int): Int = {
val max = if (value % 4 == 0) 100 else 10
val start = System.currentTimeMillis()
while (System.currentTimeMillis() - start < max) {}
value
}
It is common to encounter workloads like this when processing messages from IoT devices. Normally, the messages are small and they only contain a few samples. After a device has been off-line for a while, however, it might send a larger message which includes many samples that were buffered while it was off-line. The processing time for the larger message might be an order-of-magnitude longer compared to a smaller message.
If the stream is partitioned uniformly using Partition, as follows, the overall throughput will be limited. This is because every fourth element takes an order-of-magnitude longer to process and always goes to the same downstream consumer. Partition will backpressure when the currently selected output backpressures, so one slow downstream consumer can limit the overall throughput of the entire stream, while the other consumers remain primarily idle, since they have no incoming elements to process. In this case, the fourth consumer is the rate-limiting process for the entire stream.
val flow = Flow.fromGraph(GraphDSL.create() { implicit b =>
import GraphDSL.Implicits._
val workerCount = 4
val partition = b.add(Partition[Int](workerCount, _ % workerCount))
val merge = b.add(Merge[Int](workerCount))
for (_ <- 1 to workerCount) {
partition ~> Flow[Int].map(nonUniformSpin).async ~> merge
}
FlowShape(partition.in, merge.out)
})
Source(1 to 1000)
.via(flow)
.runWith(Sink.ignore)
In this situation, the overall throughput of the stream will be significantly faster if there is a pool of workers and the next element is sent to the next available worker. Balance can be used to achieve this partitioning.
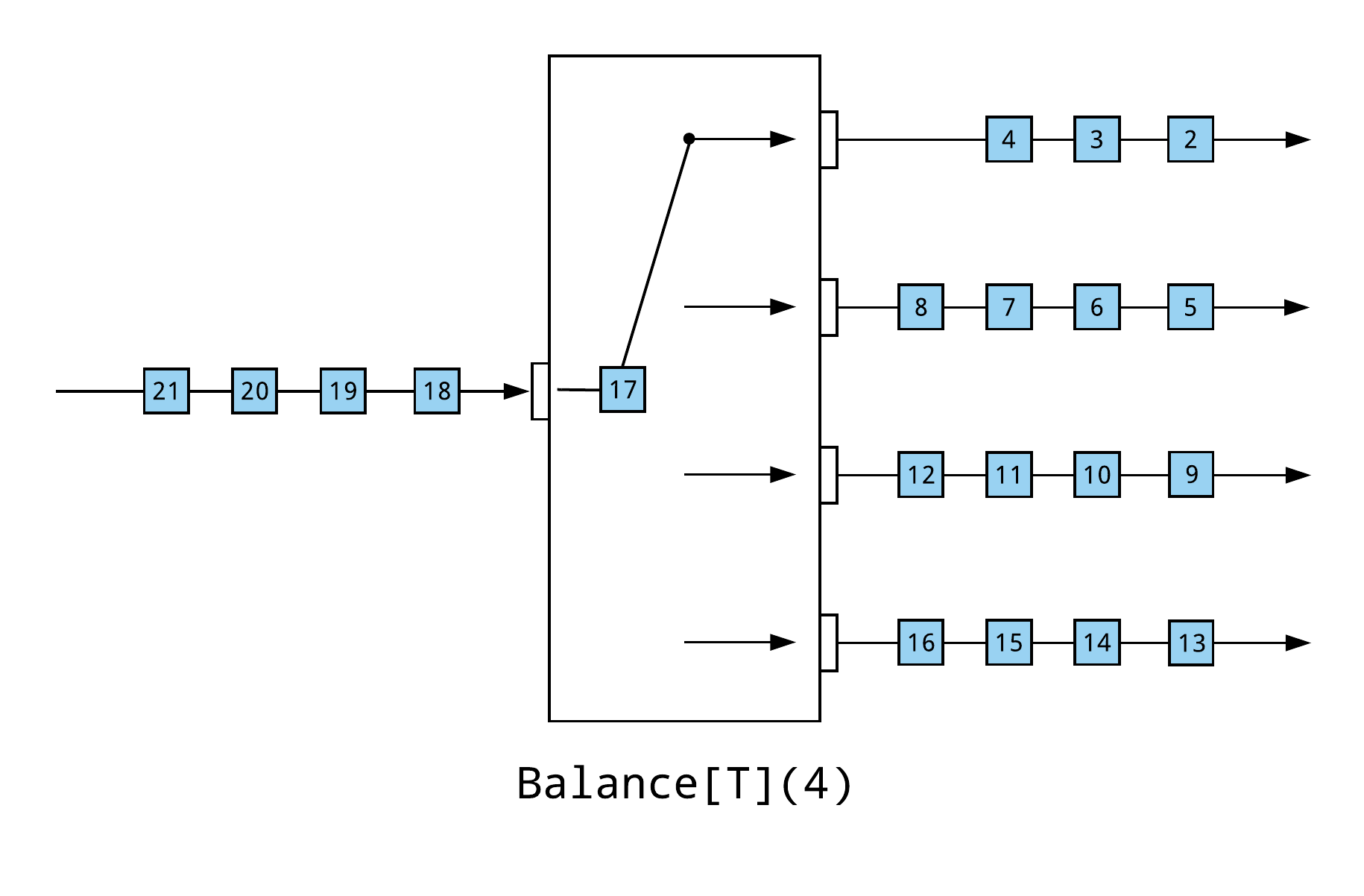
With Balance, the upstream element is emitted to the first available downstream consumer. It will not backpressure until all downstream outputs backpressure. The following example, using Balance, will execute over three-times faster than the preceding example that used Partition, by saturating all downstream consumers in parallel.
val flow = Flow.fromGraph(GraphDSL.create() { implicit b =>
import GraphDSL.Implicits._
val workerCount = 4
val balance = b.add(Balance[Int](workerCount))
val merge = b.add(Merge[Int](workerCount))
for (_ <- 1 to workerCount) {
balance ~> Flow[Int].map(spin).async ~> merge
}
FlowShape(balance.in, merge.out)
})
Source(1 to 1000)
.via(flow)
.runWith(Sink.ignore)
Note that with this approach, the stream is no longer totally ordered. Elements will be emitted downstream as soon as they complete. If the total order of the stream is important—or even the order within one partition is important, which can be common in applications that use event sourcing, or applications that involve time-series data—then this approach may not be a viable option.
groupBy
Another method that can be used to consistently partition a stream is groupBy from the Akka Streams fluent DSL. It is similar to Partition in that it demultiplexes a stream to a set of downstream consumers according to a partitioning function, but it differs from Partition in that the object returned from groupBy is a SubFlow, rather than the more common Source or Flow.
Sub-streams are completed by attaching them to a common sink—using the to method—or by merging them back together. The following example merges the sub-streams using the mergeSubstreams method.
Source(1 to 1000) .groupBy(4, _ % 4) .map(spin) .async .mergeSubstreams .runWith(Sink.ignore)
Note that the addition of async remains important for maximizing throughput. If the async was omitted, this stream would execute four-times slower, since the sub-streams would be executed on the same thread, rather than being executed concurrently. With async, this stream will execute in approximately the same time as the Partition example provided earlier in this article.
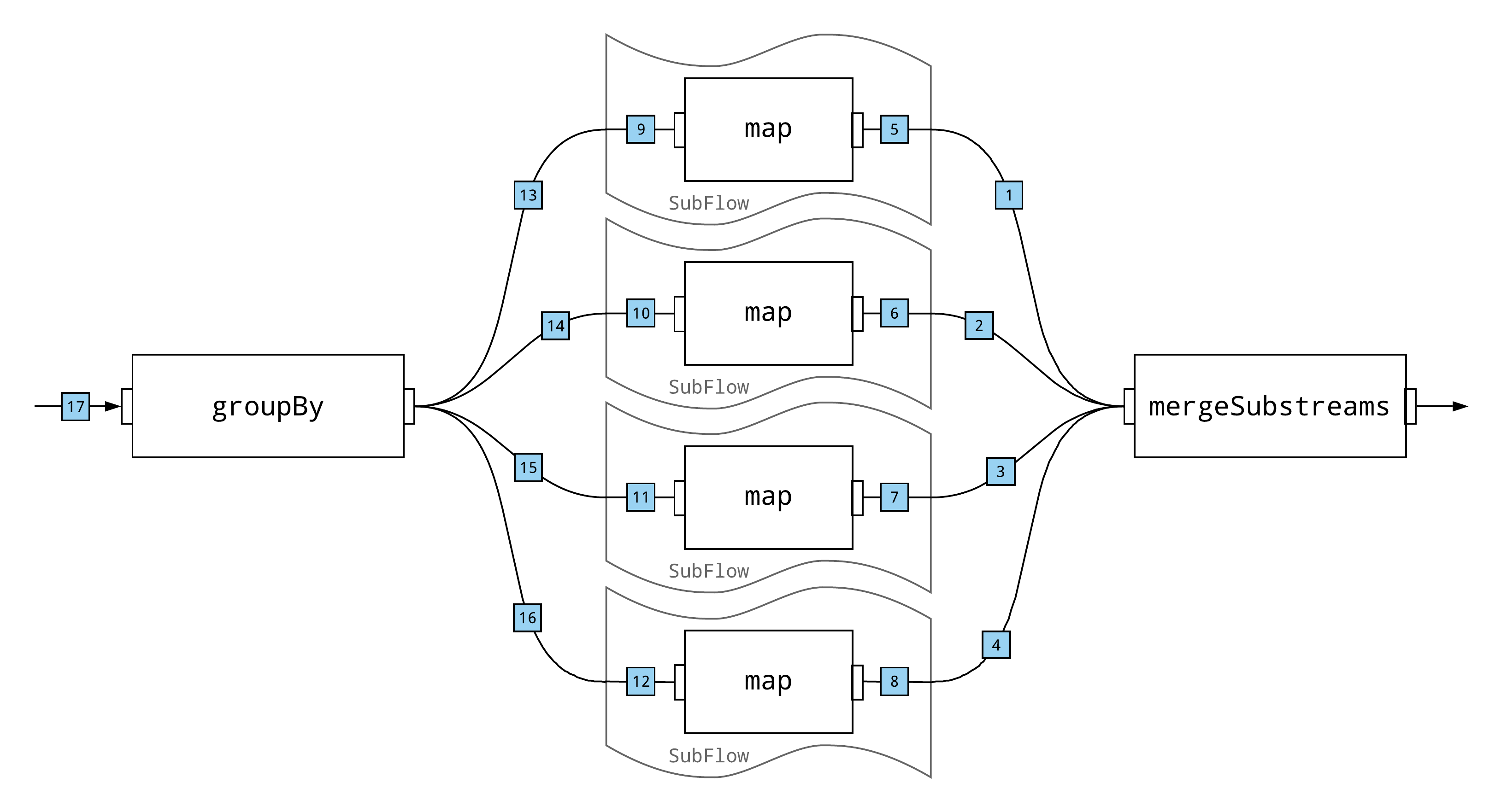
One does need to be careful when merging sub-streams. If the number of active sub-streams is limited using mergeSubstreamsWithParallelism and is less than the maximum number of sub-streams in the groupBy, the stream will deadlock, as described in the Akka Streams documentation. For example, if the active sub-streams are limited to three or fewer in the previous example, the stream will deadlock.
Source(1 to 1000) .groupBy(4, _ % 4) .map(spin) .async .mergeSubstreamsWithParallelism(3) // This will deadlock the stream! .runWith(Sink.ignore)
Another thing to be careful of with groupBy is that if you are working with a very large number of partitions, you need to be cognizant of the memory requirements. For example, it would not be a good idea to partition ephemeral session-identifiers into thousands or millions of unique sub-streams for some kind of stateful processing. The groupBy key for each partition will be in memory and there is no timeout mechanism. For this kind of processing, it would be better to maintain state in an actor and interface with the actor from the stream using mapAsync and the ask pattern, or the ask flow stage, which will maintain backpressure in the stream, as I detailed in my series on integrating actors and streams. The actor can also be used to implement a timeout mechanism, using a timer function, to stop the actor after a period of inactivity.
splitWhen and splitAfter
Similar to groupBy, splitWhen and splitAfter are two other operations that generate sub-streams. When they are suited to the workload, they can be used to greatly improve throughput, by dynamically creating sub-streams that can be executed in parallel.
Interestingly, the following example is one of the most efficient ways to execute the example workload that I have presented in this article.
Source(1 to 1000) .splitWhen(_ % 4 == 0) .map(spin) .async .mergeSubstreams .runWith(Sink.ignore)
This example arbitrarily emits a new sub-stream after every four elements. If the number of elements per sub-stream is much larger, say 1000, the performance will not be as good, since it will decrease the frequency at which sub-streams are created, ultimately decreasing the overall parallelism.
Being able to partition a workload in this manner usually depends on the workload itself. In an IoT scenario, one might partition a collection of messages from a single device based on a delimiter for individual messages. Depending on how it is used, this partitioning scheme may or may not maintain total ordering within the stream. Of course, it can also be used in combination with the other partitioning schemes presented in this article—perhaps first partitioning messages based on a unique device-identifier using Partition, then partitioning collections of messages from a single device using splitWhen or splitAfter.
Since the parallelism is basically unlimited in this case, it can make sense to limit the parallelism relative to the number of underlying CPU cores. This can be done with mergeSubstreamsWithParallelism. The following example results in no more than four sub-streams being created at any one time and a new sub-stream will not be created until one of the previous four has been merged and completed.
Source(1 to 1000) .splitWhen(_ % 4 == 0) .map(spin) .async .mergeSubstreamsWithParallelism(4) .runWith(Sink.ignore)
Summary
In this article, I explored how to partition Akka Streams, with an emphasis on maximizing throughput. When partitioning a stream to improve performance, the idea is to partition the stream so that it can maximize the use of CPU cores, or IO, depending on the type of workload. For the partitioned stages of the stream, the techniques that I explored in my previous article, on maximizing the throughput for individual streams, remain important. In a future article, I will explore how streams can be partitioned externally, to maximize scalability and provide high-availability.