Maximizing Throughput for Akka Streams
I expand on these concepts in my Scale by the Bay presentation.
The Akka Streams API is fantastic for building scalable applications that involve streaming workloads. It provides high-level semantics that naturally describe these workloads, and it handles the dynamics inherent to these systems, resulting in applications that are reliable and resilient. If you are not familiar with the Akka Streams API, I published a motivating example for adopting it, as well as an article summarizing how powerful it is for handling the common patterns encountered when streaming telemetry.
The Akka Streams API is very efficient. As long as you are not constructing extremely complex graphs, it is pretty easy to achieve impressive throughput. There are situations, however, where careful attention to how the stream is ultimately executed can greatly improve the throughput, and the overall performance and scalability of the application.
In this article, I will explore a number of techniques for maximizing the throughput of Akka Streams. Rather than constructing elaborate examples, I will provide self-contained samples, in Scala, that are easy to experiment with in isolation. This article is rather long, but I wanted it to be reasonably comprehensive.
Asynchronous Boundaries
Although it is transparent to the programmer, under the hood, Akka Streams are executed by actors. A single stream will be executed by a single actor, leveraging operator fusion, unless steps are taken to introduce asynchrony and parallelism. Operator fusion dramatically improves performance, by avoiding the asynchronous messaging overhead between actors. It also has properties sympathetic to efficient, young-generation garbage-collection. For an IO or CPU-bound workload, however, allowing different segments of the stream to execute in parallel can greatly improve the overall throughput.
The following stream executes two, simulated, CPU-bound workloads in consecutive map stages, 1000 times.
// Simulate a CPU-intensive workload that takes ~10 milliseconds
def spin(value: Int): Int = {
val start = System.currentTimeMillis()
while ((System.currentTimeMillis() - start) < 10) {}
value
}
Source(1 to 1000)
.map(spin)
.map(spin)
.runWith(Sink.ignore)
This implementation will execute synchronously, on a single thread, and take approximately twice as long as the following implementation, which will consume two threads, performing the CPU-intensive operations concurrently.
Source(1 to 1000) .map(spin) .async .map(spin) .runWith(Sink.ignore)
The addition of async means that each map stage will be executed in a separate actor, with asynchronous message-passing used to communicate between the actors, across the asynchronous boundary.
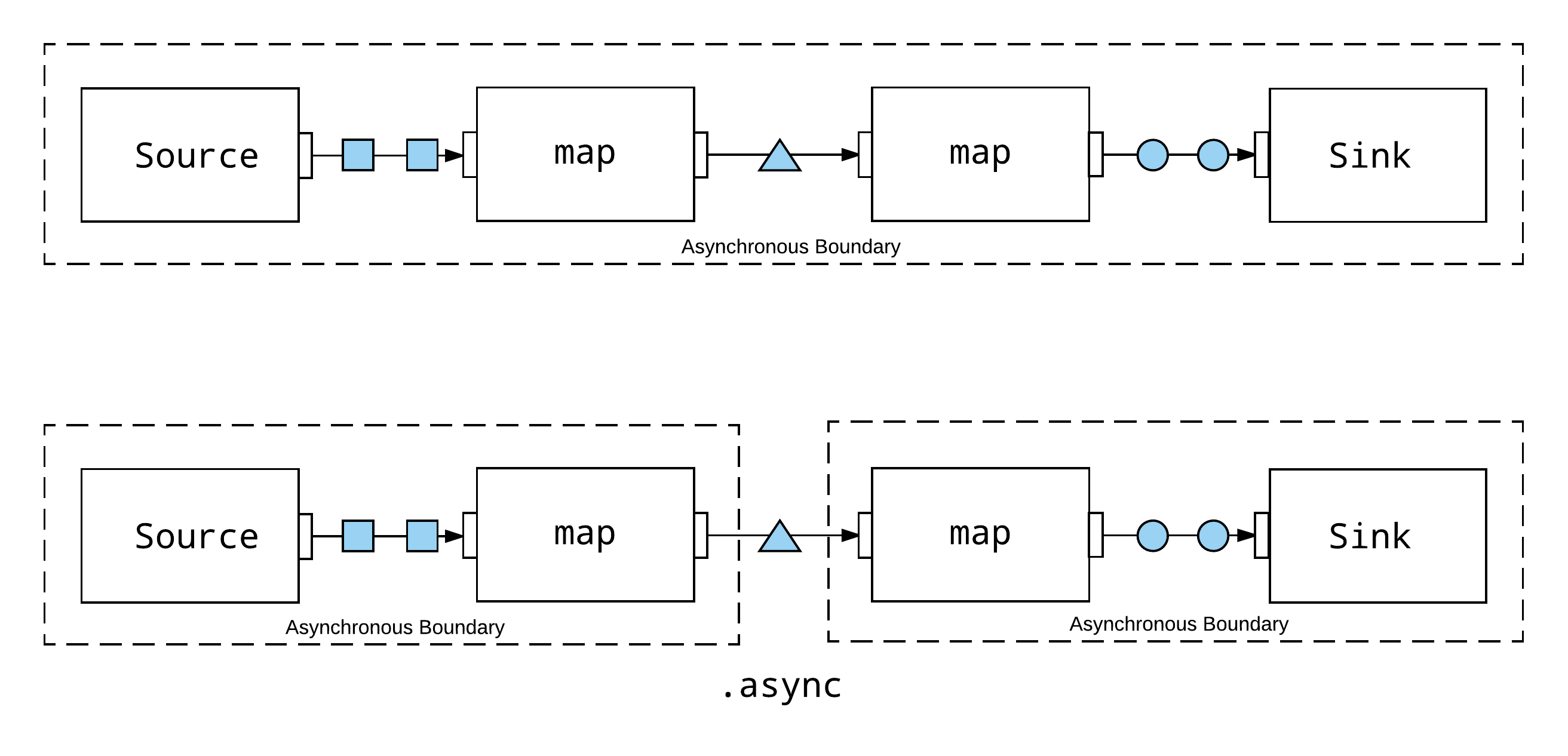
It is worth noting how easy it was to experiment with this additional parallelism, simply by adding async. In traditional, multi-threaded programming, one would need to write a significant amount of intricate code to handle locking, synchronization, and queuing, just to even run such an experiment.
Capturing Work in a Future
When a stream has a stage that performs a relatively expensive CPU-bound operation and introducing an asynchronous boundary with async does not introduce sufficient parallelism, capturing the work in a Future, and using mapAsync, can significantly increase throughput, by increasing the parallelism and saturating the available cores. The Future will most likely execute on another thread of the execution context, or even on a separate execution context, perhaps one that is dedicated to blocking workloads.
Returning to the example above, the following stream captures the simulated, CPU-bound workload in a Future and will execute just as fast as using async between the two map stages.
Source(1 to 1000) .mapAsync(1)(x => Future(spin(x))) .mapAsync(1)(x => Future(spin(x))) .runWith(Sink.ignore)
With this approach, however, the mapAsync parallelism can be increased further, to increase the throughput even more. On an eight-core machine, the following example will run four-times faster still.
Source(1 to 1000) .mapAsync(4)(x => Future(spin(x))) .mapAsync(4)(x => Future(spin(x))) .runWith(Sink.ignore)
This technique of capturing work in a Future to increase parallelism is often not used enough. Note again how easy it was to experiment with increasing the throughput, simply by using Future.apply and adjusting mapAsync parallelism, without having to introduce the intricacies of managing threads, locks, and queues in traditional systems programming. One word of caution though, be careful when capturing workloads within the Future.successful method, or you may actually decrease performance, as I detailed in a previous article.
Understanding mapAsync and async
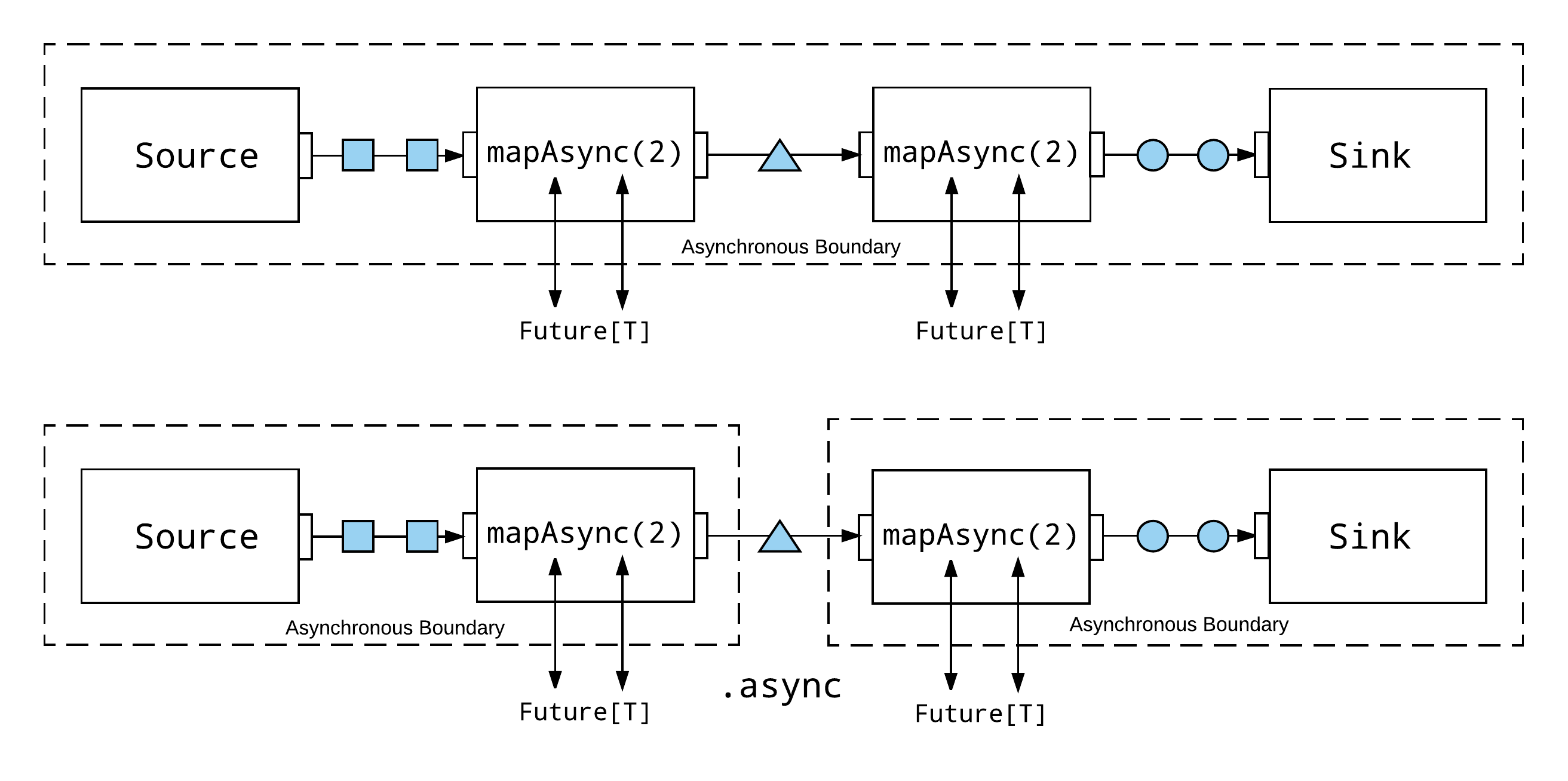
As I have just demonstrated, both async and mapAsync are means of introducing asynchrony and parallelism, but many people are unclear about the differences between the two. It is important to understand the distinction.
The mapAsync flow stage introduces asynchrony—because the Future will be executed on a thread of the execution context, rather than in-line by the actor executing the flow stage—but it does not introduce an asynchronous boundary into the flow. The mapAsync flow stage basically just manages the completion of each Future, emitting the result downstream. If there are multiple, adjacent mapAsync flow stages, they are still fused and executed by the same underlying actor.
When an asynchronous boundary is introduced, the Akka Streams API inserts a buffer between every asynchronous processing stage, to support a windowed backpressure-strategy, where new elements are requested in batches, to amortize the cost of requesting elements across the asynchronous boundary between flow stages. For more details, see the Akka Streams documentation. The default size of this buffer is 16 elements. For some workloads, introducing asynchronous boundaries even between mapAsync flow stages can further improve performance.
To illustrate, consider the following example with four consecutive mapAsync stages, each executing a different, simulated, CPU-bound workload. The duration of the workload is selected at random, uniformly distributed between 0 milliseconds and 100 milliseconds. Since there are no asynchronous boundaries, the following stream will be fused and executed by a single actor.
// Simulate a non-uniform CPU-bound workload
def uniformRandomSpin(value: Int): Future[Int] = Future {
val max = random.nextInt(101)
val start = System.currentTimeMillis()
while ((System.currentTimeMillis() - start) < max) {}
value
}
Source(1 to 1000)
.mapAsync(1)(uniformRandomSpin)
.mapAsync(1)(uniformRandomSpin)
.mapAsync(1)(uniformRandomSpin)
.mapAsync(1)(uniformRandomSpin)
.runWith(Sink.ignore)
This stream will execute more efficiently if an asynchronous boundary is inserted between each mapAsync element, to further decouple the stages.
Source(1 to 1000) .mapAsync(1)(uniformRandomSpin).async .mapAsync(1)(uniformRandomSpin).async .mapAsync(1)(uniformRandomSpin).async .mapAsync(1)(uniformRandomSpin).async .runWith(Sink.ignore)
Note that what I am simulating here is a different workload executing in each mapAsync stage, otherwise it would be even more efficient to just compose the stream as follows.
Source(1 to 1000) .mapAsync(4)(uniformRandomSpin) .runWith(Sink.ignore)
Introducing parallelism and asynchrony needs to be done with care and it always needs to be informed by the underlying workloads and how much one needs to limit parallelism.
mapAsync Parallelism
For CPU-bound workloads, I have already demonstrated the benefits of adjusting the overall mapAsync parallelism to saturate the available cores. If a workload is not CPU bound—like a non-blocking network request to another service—throughput may be improved by increasing the mapAsync parallelism well beyond the number of cores. Basically, you want to increase the parallelism, within reason, to keep the downstream saturated with work as the non-blocking requests complete.
The following example, which simulates a non-blocking network request to another service, will complete all one-thousand operations nearly simultaneously, consuming limited local resources, and complete the stream in approximately 100 milliseconds.
// Simulate a non-blocking network call to another service
def nonBlockingCall(value: Int): Future[Int] = {
val promise = Promise[Int]
val max = FiniteDuration(random.nextInt(101), MILLISECONDS)
system.scheduler.scheduleOnce(max) {
promise.success(value)
}
promise.future
}
Source(1 to 1000)
.mapAsync(1000)(nonBlockingCall)
.runWith(Sink.ignore)
It is best to avoid blocking calls in a Future whenever possible, but if it cannot be avoided—for example, when working with a legacy API—increasing the mapAsync parallelism can have a positive effect on throughput, albeit at the expense of allocating a large number of threads, and blocking execution on those threads. For more considerations for handling blocking workloads, see my article entitled Calling Blocking Code: There is No Free Lunch.
mapAsyncUnordered
The mapAsync flow stage will preserve the downstream order of each element. This means that the result of a Future will not be emitted downstream until the result of the Future preceding it has been emitted. If there is a lot of variation in how long each Future takes to complete—with perhaps some completing on the order of milliseconds, and others on the order of seconds—and preserving the downstream order is not important, mapAsyncUnordered can be used to increase throughput and more effectively saturate downstream stages, by emitting a Future as soon as it completes, independent of the overall ordering of the stream.
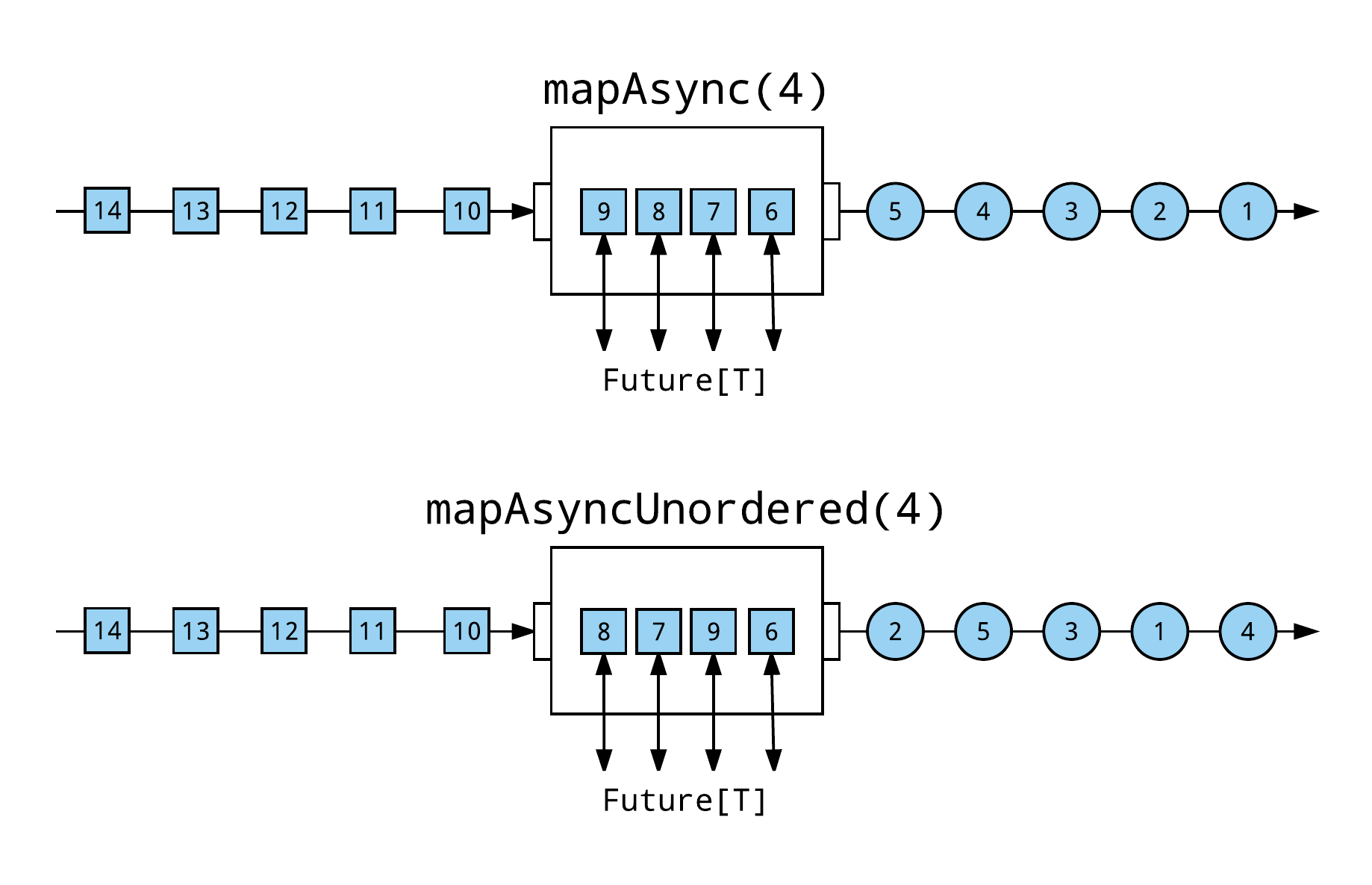
The following example emits unordered elements downstream and will complete faster than using mapAsync.
Source(1 to 1000) .mapAsyncUnordered(8)(uniformRandomSpin) .runWith(Sink.ignore)
The greater the parallelism, and the greater the variation in the time it takes to complete each Future, the more dramatic using mapAsyncUnordered can be on the overall throughput.
Async All the Things!
With all of the benefits from introducing asynchrony discussed so far, there can be a temptation to use it liberally. Why not use async to introduce an asynchronous boundary between every single flow stage? Or capture every operation in a Future and use mapAsync? Clearly, if there was a benefit from doing this, the Akka Streams API would simply implement this under the hood. The fact that operator fusing is the default and these are methods exposed in the public API, means that there are situations in which they are appropriate, and there are other situations where they are not.
The following, trivial example maps an integer through a sequence of case-class transformations. This example executes in about one second on my computer.
final case class One(value: Int) final case class Two(value: Int) final case class Three(value: Int) Source(1 to 1000000) .map(x => One(x)) .map(x => Two(x.value)) .map(x => Three(x.value)) .runWith(Sink.ignore)
If I modify this example to introduce more parallelism, by using async to insert an asynchronous boundary between every flow stage, it takes approximately twice as long to execute.
Source(1 to 1000000).async .map(x => One(x)).async .map(x => Two(x.value)).async .map(x => Three(x.value)).async .runWith(Sink.ignore)
Why is this? As I have already discussed, the first example is executed within a single actor, and all of the operations will be executed on the same thread. In the second example, each flow stage will be represented by its own actor—each of which can execute concurrently, on a different thread, with message-passing used to communicate the result between each flow stage—but this introduces the overhead of communication and synchronization among threads.
The performance is even worse if I execute these trivial workloads in a Future with mapAsync. Note that I am using Future.apply, rather than Future.successful, on purpose.
Source(1 to 1000000) .mapAsync(1)(x => Future(One(x))) .mapAsync(1)(x => Future(Two(x.value))) .mapAsync(1)(x => Future(Three(x.value))) .runWith(Sink.ignore)
When a workload is relatively expensive, the additional overhead of message-passing across the asynchronous boundary between flow stages, or executing a Future on a thread of the execution context, is insignificant compared to the benefit gained from parallelizing the stream. But if the workload is not expensive, like the trivial example presented here, this additional overhead is consequential, and will degrade the overall throughput.
Buffers
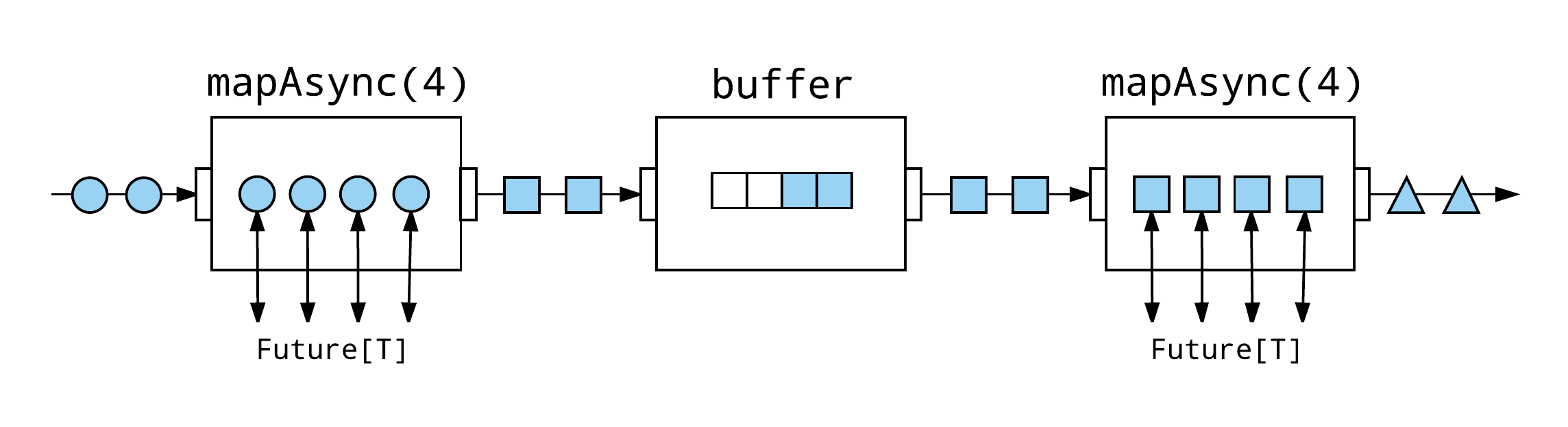
As I discussed above, when an asynchronous boundary is introduced with async, the Akka Streams API inserts a buffer between every asynchronous processing stage. As I demonstrated previously, when adjacent workloads in the stream are non-uniform, adding asynchronous boundaries can decouple adjacent stages and improve throughput. It depends on the workload, but the improvement can come from averaging the workload across the buffered elements to keep the downstream saturated with work. The same effect can sometimes be achieved by inserting explicit, user-defined buffers within the stream.
The following example has a 16-element buffer between each mapAsync stage and will execute just as fast as using the async implementation presented earlier, even though all of these flow stages are fused.
Source(1 to 1000) .mapAsync(1)(uniformRandomSpin) .buffer(16, OverflowStrategy.backpressure) .mapAsync(1)(uniformRandomSpin) .buffer(16, OverflowStrategy.backpressure) .mapAsync(1)(uniformRandomSpin) .buffer(16, OverflowStrategy.backpressure) .mapAsync(1)(uniformRandomSpin) .buffer(16, OverflowStrategy.backpressure) .runWith(Sink.ignore)
The buffer improves performance by decoupling stages, allowing the upstream or downstream to continue to process elements, on average, even if one of them is busy processing a relatively expensive workload. If the majority of the computations are fast, but there is a long tail, with only a small number of computations taking significantly longer than the average, the result of adding a buffer between two stages can be even more dramatic.
If the source of the stream polls an external entity for new messages and the downstream processing is non-uniform, inserting a buffer can be crucial to realizing good throughput. For example, a large buffer inserted after the Kafka Consumer from the Reactive Streams Kafka library can improve performance by an order of magnitude in some situations. Otherwise, the source may not poll Kafka fast enough to keep the downstream saturated with work, with the source oscillating between backpressuring and polling Kafka.
val kafkaSource =
Consumer.committableSource(consumerSettings, Subscriptions.topics(topic))
.buffer(10000, OverflowStrategy.backpressure)
Similar to the async method discussed in the previous section, it should be noted that inserting buffers indiscriminately will not improve performance and simply consume additional resources. If adjacent workloads are relatively uniform, the addition of a buffer will not change the performance, as the overall performance of the stream will simply be dominated by the slowest processing stage. The following example does not benefit from the addition of the buffer stage.
// Simulate a constant CPU-bound workload
def constantSpin(value: Int): Future[Int] = Future {
val max = 50
val start = System.currentTimeMillis()
while ((System.currentTimeMillis() - start) < max) {}
value
}
Source(1 to 1000)
.mapAsync(4)(constantSpin)
.buffer(1000, OverflowStrategy.backpressure)
.mapAsync(4)(constantSpin)
.runWith(Sink.ignore)
As a final note on buffers, the mapAsync parallelism parameter essentially defines the size of the internal buffer that is used to manage the number of outstanding Futures. As a result, in some situations, increasing the mapAsyc parallelism can have the same effect as adding an explicit buffer element.
Make Exceptions Exceptional
If processing an element in the stream results in an exception, the Akka Streams API offers convenient supervision strategies for handling the exception. The element can be discarded and the stream will continue; the element can be discarded and the current stage restarted, which will also discard any intermediate state in the process, before resuming the stream; or the stream can be stopped altogether. Supervision strategies can be applied to individual processing stages, or to the materializer of the stream as a whole.
If a message is not of interest, or does not conform to a whitelist—for example, processing a message queue where a significant number of messages are in a legacy format—it may seem like a reasonable strategy to simply throw an exception and let the stream supervisor drop the message. But if a stream is processing a large number of messages and using exceptions for basic error-handling, this can negatively impact performance. Exceptions should only be used for exceptional situations. A better approach is to use the filter, collect, or mapConcat in-line flow stages to handle these common and expected situations.
The following stream throws an exception and has the stream supervisor discard the message for 99 percent of all messages.
val decider: Supervision.Decider = {
case _ => Supervision.Resume
}
implicit val materializer = ActorMaterializer(
ActorMaterializerSettings(system).withSupervisionStrategy(decider))
Source(1 to 1000000)
.map(x => if (x % 100 == 1) x else throw new Exception("Oh no!"))
.runWith(Sink.ignore)
If instead, a filter is used to handle the unwanted messages, the stream runs two orders-of-magnitude faster.
Source(1 to 1000000) .filter(x => if (x % 100 == 1) true else false) .runWith(Sink.ignore)
If elements need to be transformed as part of the filtering, similar performance can be achieved with the collect or mapConcat flow stages.
Source(1 to 1000000)
.collect({
case x if x % 100 == 1 => x * 2
})
.runWith(Sink.ignore)
Source(1 to 1000000)
.mapConcat(x => if (x % 100 == 1) x * 2 :: Nil else Nil)
.runWith(Sink.ignore)
As always, it is important to test and make sure the performance meets your expectations.
Summary
In this article, I explored the basic techniques for maximizing the throughput of an Akka Stream. I have demonstrated how easy it is to experiment with modifications to the stream, in order to maximize throughput, without having to introduce threads, locks, or even write a considerable amount of code.
For inexpensive or uniform adjacent workloads, operator fusing results in great throughput. For expensive, IO or CPU-bound workloads, it is important to add asynchrony to maximize concurrency. When workloads are non-uniform, adding asynchrony, or adding buffers, can be important. In other situations, attention to error handling, or even limiting concurrency, can be essential to maximizing throughput. In another article, I will explore how streams can be partitioned to improve throughput. Happy hAkking!