Shared-Nothing Architectures for Server Replication and Synchronization
I spent over a decade working on a software platform for time-series data and events that is widely used in industry. It supports a diverse set of applications—like supply-chain management, condition-based maintenance, regulatory compliance, and process monitoring, optimization, and control—in industries including manufacturing, power generation, utilities, oil and gas, and chemical processing.
A core component of the platform is a proprietary, purpose-built, time-series database. After spending a few years working on agents for collecting time-series data—mainly drivers embedded in SCADA systems—I joined the team responsible for the time-series database proper. I joined this team to participate in a high-profile project to evolve the single-instance database into a clustered architecture to support high-availability and ensure the continuity of time-series reads and writes through failures or planned maintenance. High-availability and disaster recovery were becoming increasingly important operational and regulatory requirements, especially for our customers involved in the transmission and distribution of electricity, and the refining and transportation of oil and gas.
The initial release of the high-availability platform used a pragmatic, shared-nothing[1] approach for time-series data replication. This was years before the release of Amazon's DynamoDB, or the open-source Apache Cassandra, two systems that are notable for the introduction of a hinted-handoff model to synchronize data within a cluster of symmetric servers.[2] It was also years before the rise of messaging systems that rely on the replication of a write-ahead log, largely popularized by Apache Kafka.[3] We intended to eventually support a mechanism for the intra-cluster replication of time-series writes. However, despite having a design and communicating this roadmap to our customers, it never became a priority, and it was never implemented. While the system was arguably less sophisticated, for most customers, it worked just fine without it.
Years later, after gaining operational experience with server architectures that rely on intra-cluster replication, in retrospect, I think a shared-nothing approach remains superior, especially for systems that process essentially unbounded streams of time-series data and events. With the ubiquity of distributed journals in modern software infrastructures—services like Apache Kafka, Apache Pulsar, Amazon Kinesis, Azure Event Hubs, Google Pub/Sub, and the like—it makes a shared-nothing approach even more compelling.
This article details the approach we took to clustering the single-server, time-series database and uses this story as a backdrop to contrast the benefits and drawbacks of intra-cluster replication compared to a shared-nothing architecture for server synchronization. This article concludes with some reflections on consistency models for distributed journals.
Toward a Clustered Architecture
The single-instance, time-series database was a well-established product, approximately a decade old. The server was composed of multiple processes: one for managing TCP connections and message routing; one for managing series metadata and configuration; one for performing time-series writes to the write-ahead log, in addition to tracking the last value for each series;[4] one for reading from, and writing to, the time-series database files on disk; and, finally, a process to support publish-subscribe messaging for time-series data, which was mainly used for actively updating graphs on operator consoles, in near real-time. Essentially, this time-series database employed a microservices architecture a few decades before this became a popular term. The processes were always installed on a single server, but, theoretically, since the subsystems relied primarily on immutable messaging for inter-process communication, they could have been distributed across different servers.
Our initial approach for providing high-availability was to designate one server as the primary server. The primary server is the only server where configuration changes can be made. For example, changing the name or the metadata of a series, or adjusting policies for authentication and authorization. Configuration changes are journalled on the primary server. There is a journal dedicated to each replica sever. Most systems had between one and five replicas. The replicas independently consume from their journal, using the publish-subscribe subsystem on the primary server, to synchronize configuration changes. The servers gossip the last configuration change they have consumed and they use it to advertise themselves as unavailable if they are not up-to-date.
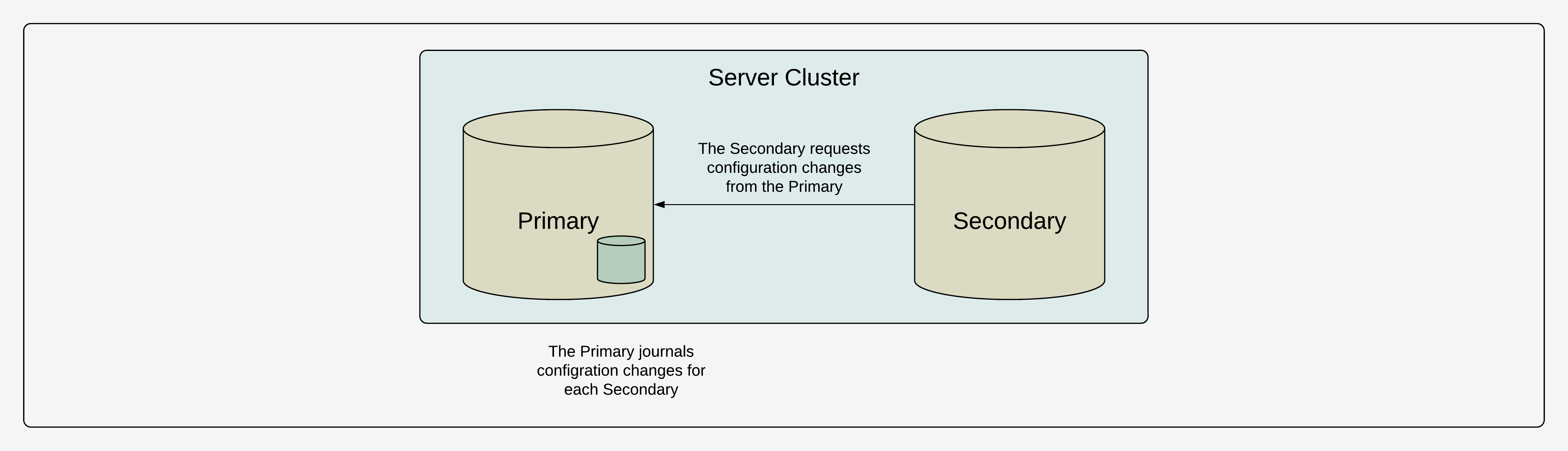
The replicas are only eventually-consistent, but this is a common trade-off in highly-available systems. Each replica is a full replica of the primary server. In other words, there is no sharding within the cluster itself—all servers have all of the data. If the primary server is unavailable, no configuration changes can be made. However, even if the primary server is unavailable, each replica can still process time-series reads and writes for all existing series, providing high-availability for most applications. If the primary server is irrecoverably lost, there is a manual process to designate a replica as the new primary. These trade-offs were acceptable, even desirable, given the relatively static, industrial environments in which these systems are deployed.
The time-series data are replicated in the cluster by making the data collection agents responsible for writing the data to every server in the cluster. A client can query the time-series data, or subscribe to time-series updates for a set of series, from any server within the cluster. The servers can be behind a load balancer, or the client itself can dynamically select a server based on the cluster status, in a prioritized or round-robin fashion.
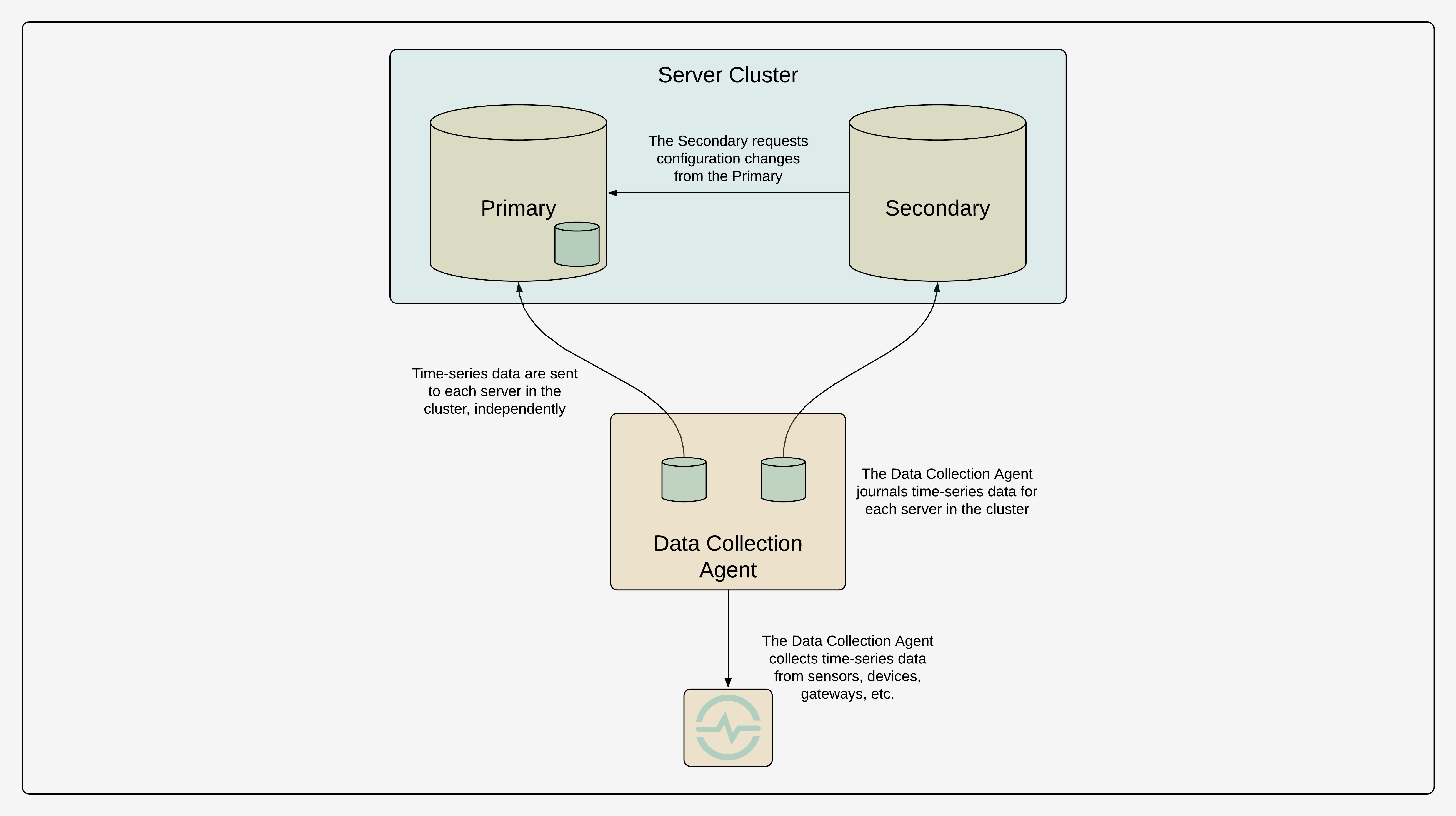
The architecture supports topologies where some replicas are isolated on a control network dedicated to operations, or even situated miles away in a backup control-centre to satisfy regulatory requirements, while other replicas are only available on the corporate network for analysts, reporting, and other business functions. Critical to the design was allowing each server to operate independently with respect to time-series reads and writes. Each server can support hundreds of thousand of time-series reads and writes per second and it was important to avoid overhead for the sake of consistency that would negatively impact operational performance or availability.
It may seem undesirable to have the client responsible for synchronizing writes to every server in the cluster, but these systems were generally installed in manufacturing or industrial environments where there were a manageable number of agents, usually at fixed locations. Generally, the topologies were relatively small and static.[5] For instance, the majority of the data in the system would often come from one agent reading telemetry and event data from a single SCADA system that already aggregated the data. The writes were almost always append-only, which is typical of time-series data collection. To improve reliability and prevent data loss in the event that a data collection agent was restarted, the agents journalled writes to disk. They maintained an independent journal for each server in the cluster. It was easy to dedicate enough local, reliable storage to these agents such that they could buffer writes for days or weeks in the event of an extended network partition to one of the servers in the cluster, which could happen if the agent was running in a remote location, like on an oil platform. Given the relatively static nature of most deployments, it was an easy architecture for most customers to configure and manage.
This pragmatic approach worked quite well, especially because we avoided the need to implement or test complex algorithms for dynamic leader-election,[6] sharding, replication, rebalancing, or multi-master writes. It allowed our small development team to provide value to customers reasonably quickly, despite the project being a significant development effort.[7] However, the approach was not without drawbacks. While the replicas synchronize their configuration with the primary server, and it is easy to tell when a replica is up-to-date, there is no easy way to tell which servers are synchronized in terms of the time-series data. There is no native support for quorum reads, read-repair, or anti-entropy repair.[8] Servers can permanently diverge if there are inconsistencies or failures in time-series writes.
Adding Intra-Cluster Replication
As I already detailed, replicating the time-series data to the cluster from the remote agents worked well given the relatively static topologies, append-only writes, and the durability guarantees provided by the agents journalling writes locally. These agents handled the vast majority of the writes in the system. A big challenge was the small number of writes, updates, and deletes coming from end-user applications that were only connected to a single server. For example, an operator annotating a sensor measurement in a graphical display, or appending a value to a manually-entered series. Recall that any sever in the cluster can handle these requests and they are handled independently—it is only configuration changes that must be handled by the primary server, and it is only these configuration changes that are replicated within the cluster itself. If an event is appended, modified, or deleted on a single server, only that server will reflect the change and the other servers in the cluster will never have this information.
We decided against addressing the problem of intra-cluster, time-series data replication in the first release of the high-availability product, since it only impacted a minority of customers. Our plan for eventually handling these requests was for the server accepting the request to journal it in a dedicated, memory-mapped, write-ahead log, one for every server in the cluster, durably persisted to the file system. The other servers in the cluster would request the data from this journal to synchronize the time-series data cluster-wide, a similar mechanism to how configuration changes were already synchronized within the cluster.
On the surface, our plan for intra-cluster, time-series data replication seemed great. The cluster would remain available for reads and writes in the event of individual server failures; the cluster would be resilient, since it would repair itself once a failed server was available again; and the sophisticated management of data replication would be contained within the cluster itself, without the need for external dependencies, sophisticated clients, or manual intervention. However, if you have engineered or operated a system that relies on intra-cluster replication, you realize that this sophistication has some significant drawbacks. For example, consider conflicts. What if an operator connected to one server annotates a sample simultaneously with another operator annotating, revising, or deleting the same sample? How should this data be synchronized? How should it be represented on read? Also, when is a write successful? When the write has been durably persisted by one server, the majority of servers, or all servers? Does the client need to be able to read its own writes? Finally, consider resource limitations. What if the disk space for the time-series journal is exhausted? How should the cluster degrade or fail?
We had a certain attachment to this hint-handoff style architecture for the intra-cluster replication of time-series data. It felt like it was required to complete our sophisticated, high-availability product. As time went on, however, it never became important enough for us to actually implement. In the end, the approach we took to solving the problem of interactive requests was similar to that of the existing data-collection agents: make the client responsible for writing time-series data, consistently, to all servers in the cluster. This approach, while quite imperfect, worked reasonably well in most cases, particularly when manual writes originated from only a small number of operator consoles or devices.
The Problems with Hinted Handoff
A fundamental problem with a hinted-handoff style architecture, is that when a server in the cluster fails, or is network partitioned, the remaining servers in the cluster must work significantly harder. Not only do these servers need to continue to process writes and serve requests, these servers must also serve more requests than normal, accepting the requests that would have otherwise been processed by the failed server. In addition, the remaining servers must journal writes for the failed server so that they can be consumed at a later point in time. Therefore, even when a single server is unavailable, the remaining servers must perform significantly more input and output (IO). This is a poor architecture for load-shedding and is the opposite of what we want in this situation: when the cluster is already in a degraded state, it must work harder.
Once the cluster is able to communicate again, things do not get much better. Over and above continuing to journal writes and serve more requests than normal, the servers must perform even more IO to serve writes from the journal as the failed server catches up. In addition, if the failure was the result of a network partition, producers of writes may be attempting to offload buffered data as quickly as possible, especially if they have a limited capacity to buffer writes locally due to limitations on memory or storage. This is also the exact opposite of what we want: when the cluster is trying to heal and is in one of its most delicate states, it is also under maximum stress.
The situation can be improved by dedicating storage partitions for the hinted-handoff journals, so that each journal has dedicated IO and storage capacity. For example, one could dedicate enough storage capacity for a failed server to be offline for a long weekend, without a catastrophic loss of data. But this also highlights additional problems of these journals: they are dedicated to a single server, rather than being shared; they are of limited capacity; they cannot be centrally managed; and there are limited options for scaling them independently. Depending on the write consistency, hinted-handoff systems are still vulnerable to a hardware failure on a single server. If the data in the hinted-handoff journal of a coordinator has not yet been synchronized to the replicas, it can be lost catastrophically.
Finally, a significant problem with a hinted-handoff approach is that operationally, hinted-handoff growth is a noisy signal that tends to draw a lot of attention without always being actionable. Sometimes hinted-handoff growth is the precursor to a serious failure of the cluster that may include the catastrophic loss of data, whereas other times, hinted-handoff growth is simply the temporary result of a server restarting, or from a high-volume of writes, like when backfilling data. It is hard to know when to take action, so people naturally start to ignore this important metric.
A Shared-Nothing Approach
Many systems that need reliable data ingestion—operational systems, IoT systems, industrial systems, web services—already write to a distributed, durable journal before the data are ingested into database systems. Apache Kafka is a popular system for this. Journalling writes before the database is superior to a hinted-handoff approach in many ways. First of all, the journalling system has its own resource pool and it can be scaled independently to meet requirements in terms of reads, writes, and data retention. Second, the journal can be shared, with minimal data duplication, such that it can be consumed not just into one database cluster, but into many database clusters, and also shared with streaming-data systems, or data warehouse systems. Third, after a database server fails and becomes available again, rather than burdening other servers in the cluster to read the hinted-handoff journal, it simply catches up independently by reading the shared journal. Fourth, the shared journal can impose its own access controls and traffic shaping policies. Fifth, it decouples producers and consumers and allows the system to accommodate messaging dynamics and component failures. Finally, the shared journal can be used as medium to long-term storage, including leveraging mechanisms like a compacted topic, which is useful for re-ingesting the data and is complimentary for disaster recovery.
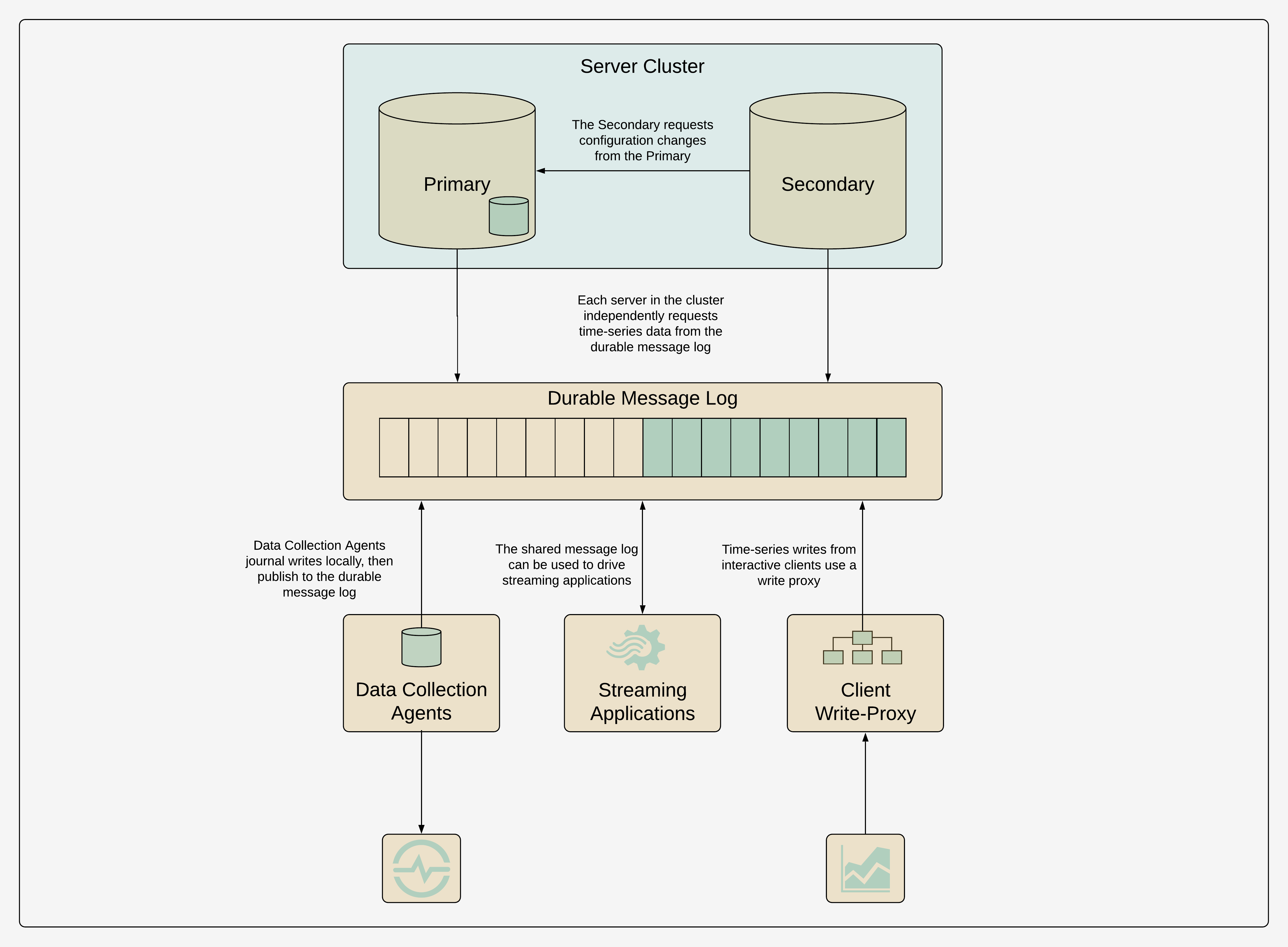
Inspecting the offsets into the shared journal for each replica—for example, the Kafka consumer offsets—can be used to determine which replicas are up-to-date. A query planner can use this metadata to route queries to the most up-to-date replica. This approach works well when one replica is unavailable but there remain enough up-to-date replicas to serve the volume of requests. Care must be taken to avoid overloading individual replicas by always sending all queries to the most up-to-date replica. However, if no servers are up-to-date, or not enough servers are up-to-date, the query planner can fail-fast, explicitly communicating this fact to the client, without the client having to infer the timeliness of the data, empirically.[9]
It is interesting to see InfluxDB, a time-series data platform similar to the one I worked on, move from using a hinted-handoff approach in the first generation of its cloud and enterprise platforms, to a shared-nothing approach in the second generation of these platforms. The article InfluxDB and Kafka: How InfluxData Uses Kafka in Production[10] details the shared-nothing architecture and the talk Lessons and Observations Scaling a Time Series Database, by Ryan Betts, provides an excellent summary of the drawbacks of the hinted-handoff architecture.
This is the first system that I have worked on that has a hinted-handoff system in it and I would never voluntarily build this model of consistency repair again.
—Ryan Betts
What About Write-Ahead Log Replication?
Write-ahead log replication, like what is used by Apache Kafka, is similar to hinted-handoff for intra-cluster replication, so why does it not suffer from the same drawbacks? In essence, it does. For example, under-replicated partitions is Kafka's equivalent of hinted-handoff growth.[11] This is an important metric to monitor for a Kafka cluster, since it is an early warning sign of brokers being offline, brokers being network partitioned, configuration issues, or cluster-wide issues. If a broker is irrecoverably failed and a new one must be introduced to the cluster, it must synchronize partitions, putting additional load on the remaining brokers, while the cluster as a whole remains under-resourced. The same is true if the cluster must be scaled or repartitioned. For instance, if the cluster is already at 90% utilization, it can be too late to take action. Adding a broker may ultimately solve the problem, but adding a broker and moving partitions will likely stress the IO and CPU even more, to the point where both adding a broker and continuing to serve existing load is impossible. It is a good idea to proactively scale these systems once they are at 70% utilization.
Despite similar challenges, however, write-ahead log replication is arguably simpler. Since these are inherently journalling systems, the replicas can simply follow the journal of the leader for the partition, without the additional complexities of hinted-handoff management. This makes write-ahead log replication easy to reason about and manage.[12] It can also be argued that this type of data replication is an essential complexity of a distributed journalling system—it is the primary job of the system—whereas it is arguably not an essential complexity of a server cluster like InfluxDB or the time-series database that I worked on.[13]
Consistency Models for Distributed Journals
A few years after completing the server high-availability project, I worked on a project to develop a durable, publish-subscribe messaging system that could be used to reliably share large quantities of time-series data between on-premises systems through the cloud. This system was developed a few years before the release of Apache Kafka, but, in many ways, it was very similar: it had the notion of a virtual, global offset into the journal; offsets were managed by the client, not the server; and it used files of a few gigabytes in size to efficiently drop data once it was older than the retention policy.[14] Finding the file to read from was a constant time operation, since it could be inferred from the offset the consumer was trying to read from. In addition, it had some nice features, like storing the hash of a write so that we could guarantee the consistency of a read and prevent software defects.[15]
Quite different from Kafka, however, instead of developing mechanisms for synchronizing data among servers in a cluster, we used the approach of appending immutable pages to blob storage managed by a cloud provider. Since the cloud provider handled the consistent replication of the blob—both within the data centre and to remote data centres—it greatly simplified the implementation.[16] There was no need to manage hinted-handoff style consistency or write-ahead log replication ourselves. The brokers writing to the journal were linearly scalable and stateless,[17] with the exception of locking the journal header on write.[18] The brokers reading from the journal were linearly scalable, stateless, and lock-free, since they could read based on their virtual view of the journal without impacting concurrent writes. The blob-storage service provided read isolation automatically, which improved performance even further. We could increase or decrease the storage capacity, flexibly and cost effectively, without the need for expensive rebalance mechanisms to move data around. Finally, we were able to iterate and adapt the stateless brokers, even testing different functionality through different endpoints, without ever having to modify the data or the software in the storage layer.[19]
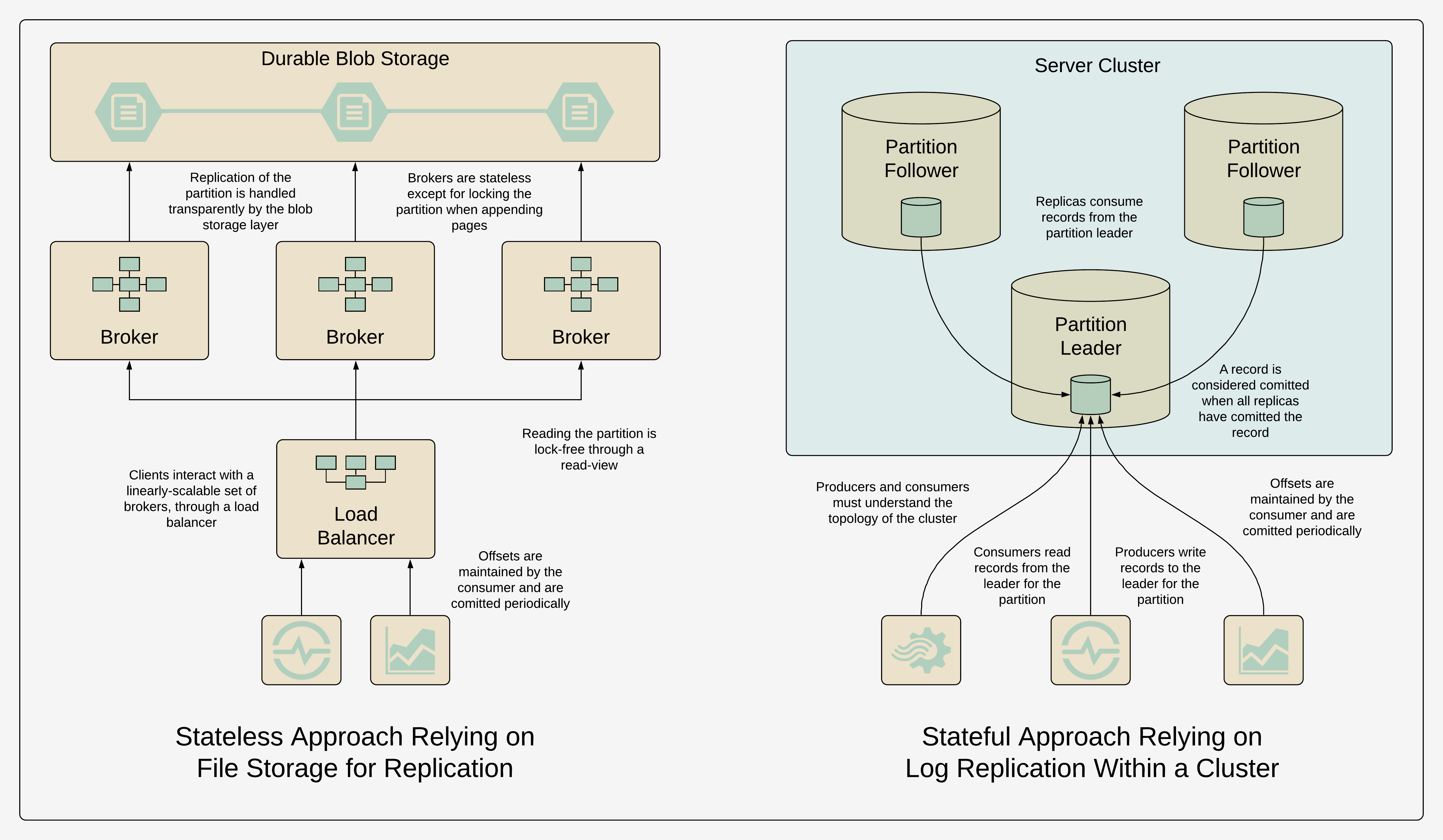
Unfortunately, at the time, there was no on-premises equivalent of this page-blob storage, so we could not use it as a fundamental infrastructure for the time-series server replication. If the technology was available, we could have used it to improve our shared-nothing approach by having the data collection agents write once to the distributed journal, rather than independently write to each replica in the cluster, then have each replica consume from the shared journal. Using this distributed journal as part of the on-premises architecture could have also addressed the problem of stateful, streaming services, like calculation engines or aggregation services, subscribing to time-series and events. As I mentioned earlier, the time-series server had a publish-subscribe mechanism, but it was server-centric, rather than cluster-centric, and was intended for ephemeral subscriptions from interactive applications, like dashboards, rather than providing a durable, high-volume subscription mechanism.[20]
Taking a Hint
A hinted-handoff model for intra-cluster replication is a sophisticated approach. It allows systems like DynamoDB and Apache Cassandra to achieve incredible reliability and resiliency.[21] The same is true for messaging systems that use write-ahead log replication, like Apache Kafka. Operationally, however, these can be challenging systems to manage, especially when workloads are non-uniform. A shared-nothing approach to server replication, notably one that incorporates a shared, distributed journal, is a far more reliable, flexible, and powerful approach, particularly for systems focused on time-series and events. It leaves the essential complexity of state replication to one system, rather than many.
There is no such thing as a completely shared-nothing architecture. Even independent servers will have some components in common, for example, a shared message queue, control plane, load balancer, logging infrastructure, or authorization system. But the term "shared nothing" is descriptive in terms of an individual, symmetric server having no direct dependency on any other server in the cluster for its operation. In our case, the handling of time-series read and write request. See the paper Locality, Statefulness, and Causality in Distributed Information Systems, by Mark Burgess, for a more complete exploration and definition of shared nothing. ↩︎
See the seminal paper from Amazon on Dynamo for a description of hinted handoff for durability and data replication and anti-entropy to repair divergent replicas after permanent failures: Dynamo: Amazon’s Highly Available Key-value Store . ↩︎
The excellent article by Jay Kreps The Log: What every software engineer should know about real-time data's unifying abstraction details why a messaging abstraction focused around a shared write-ahead log is so powerful, with benefits for performance, scalability, consistency, and systems integration. ↩︎
Finding the last value of a time series can be expensive, since it is an unbounded search backward in time—a classic problem in time-series databases. To make queries for the last value extremely efficient, we used a separate table to track the last value for each series. ↩︎
This is changing as manufacturing environments become more dynamic, or as these systems extend to the Internet to manage IoT devices. ↩︎
This was years before RAFT. While it would have been an interesting intellectual and technical challenge, we were understandably weary of implementing custom protocols for distributed consensus. ↩︎
Despite the introduction of the high-availability product, many customers were satisfied with continuing to run single-instance servers, accompanied by robust procedures for backup and recovery. For some customers, the licensing model of the high-availability product had some influence on this decision. See my article Licensing Software for Mutual Success for an exploration of how licensing models can promote suboptimal decisions. ↩︎
A quorum read is a way of letting the client decide how to handle the response based on how many servers in the cluster have the data. Read-repair is a way of synchronizing data across servers in the cluster on read, resolving discrepancies, and writing the data back to the servers participating in the read request. Anti-entropy is a technique for running read repair, periodically, as a background process. ↩︎
A feature we were asked to support many times was "guaranteed writes", where the time-series database would acknowledge the write request by a data collection agent only after persisting the data durably to disk, indexing it, and making it available for read. To my knowledge, this feature was never implemented, but leveraging the offsets into the shared journal as a transaction mechanism would have been one approach to implementing this feature. ↩︎
I disagree with some of the drawbacks of the database write-ahead log noted in the article. The write-ahead log can be larger than memory, as long as it is paged, and the write-ahead log can be just as fast and efficient as Kafka, as long as it uses similar memory-mapping or zero-copy techniques. We used both of these techniques in the time-series database that I worked on. ↩︎
See the presentation Monitoring Apache Kafka, by Gwen Shapira, for more information on effectively monitoring Apache Kafka. ↩︎
The RAFT protocol for distributed consensus is known for being understandable and tractable. It essentially uses write-ahead log replication, with a leader and a set of followers, to achieve distributed state-machine replication. ↩︎
See the series Building a Distributed Log from Scratch, by Tyler Treat, for a detailed, technical description of write-ahead log replication for messaging systems, including descriptions of Apache Kafka, NATS Streaming, and Liftbridge. This series also includes an excellent discussion of the design trade-offs. ↩︎
As we were developing this distributed-journalling service, I eventually came across the release of the Apache Kafka project. As an engineer, I was disappointed to see that it was so similar to our design, at least from the perspective of offset management and retention policies. This meant our design was not novel. However, the fact that another system landed on a very similar design to address similar requirements also reaffirmed that we had a good design. ↩︎
The hashing feature was inspired by James Hamilton's article Observations on Errors, Corrections, & Trust of Dependent Systems. ↩︎
See the paper Windows Azure Storage: A Highly Available
Cloud Storage Service with Strong Consistency and the accompanying talk for details on how Microsoft implemented Azure Storage, including techniques for data redundancy, consistency, and replication. ↩︎Again, see the paper Locality, Statefulness, and Causality in Distributed Information Systems, by Mark Burgess, for a definition of stateless: "Statelessness refers to memorylessness in the sense of a Markov process: the dependence on current state is inevitable as long as there is input to a process, but dependence of behaviour on an accumulation of state over many iterations is what people usually mean by stateful behaviour." ↩︎
Locking was handled through leases on the blob, so we did not have to introduce a system like Apache Zookeeper, or write our own locking mechanism. It was critical, however, that a broker performing a write respect the expiration of the lease. ↩︎
Apache Pulsar has landed on a similar architecture which has similar advantages. See the presentation Apache Pulsar 101: Architecture, Concepts & Benchmarks, by Quentin Adam and Steven Le Roux, for an introduction to the architecture and the many benefits. ↩︎
An alternative approach would be to replicate consumer subscriptions and offsets within the cluster, similar to what NATS Streaming does, as described in the article Building a Distributed Log from Scratch, Part 3: Scaling Message Delivery by Tyler Treat. ↩︎
I have been amazed watching an Apache Cassandra cluster operate incredibly reliably despite outright neglect. ↩︎