Masking the Problem: Representing Complex State Without Strings
A number of factors have contributed to the widespread use of strings for representing complex information in computing. HTTP, a text-based protocol, and HTML, a text-based mark-up language, became the foundations of the Internet. JSON, which is essentially a formatted string of keys and values, became ubiquitous for HTTP APIs in service-based architectures because it is human readable, flexible, extensible, and self-describing. Databases for storing and indexing JSON documents became popular. Even relational databases introduced support for JSON records. JSON and CSV have been used as a file format for block storage and data lakes.
JSON documents are often denormalized and stored in columnar or time-series databases that enable efficient batch and time-series analysis of the data. The focus of these big-data tools is generally on the partitioning of data and the distribution of computation rather than on efficiency, as long as the solution is acceptably cost effective. The denormalization of data helped answer questions that could not be answered before with huge amounts of data.[1]
Industrial computing has always favoured far more efficient representations of complex data to address the prominent constraints on memory, bandwidth, storage, computation, and power consumption. It is common to use bit fields to pack a significant amount of data into only a few bytes. A binary value, like the fact that a breaker is open or closed or the level in a tank is low, can be represented using a single bit. Whereas a string representation could take hundreds or thousands of bytes, a single 32-bit integer can atomically represent up to 32 different states.
With the increasing demands on Internet-connected devices, services, and applications, like the ones in IoT that generate huge amounts of information, it is time to return to more dense representations of data. Taking inspiration from the foundations of industrial computing, I will explore the benefits and challenges of using bit fields to represent complex state while also providing efficient storage, query, and exchange of information in cloud services.
Alarms and Events
Industrial computing usually draws a distinction between an alarm and an event. An alarm is a condition that is actionable by an operator or automation, like the opening of a pressure relief value or an electrical circuit breaker, or software determining that one or more signals is outside an acceptable range or sequence. An event is something of interest for providing context or analysing data after the fact, but is not necessarily actionable: a high ambient air-temperature, a motor starting, a valve closing, or a battery completing a charge.
Alarms and events often carry a time-series component. For example, when the high pressure alarm started and when the pressure returned to normal, or when a battery started discharging and when it stopped. The time span of an alarm or an event can be correlated with other telemetry, like measurements of pressure, temperature, flow rate, or frequency, to provide context for calculations or data visualizations.
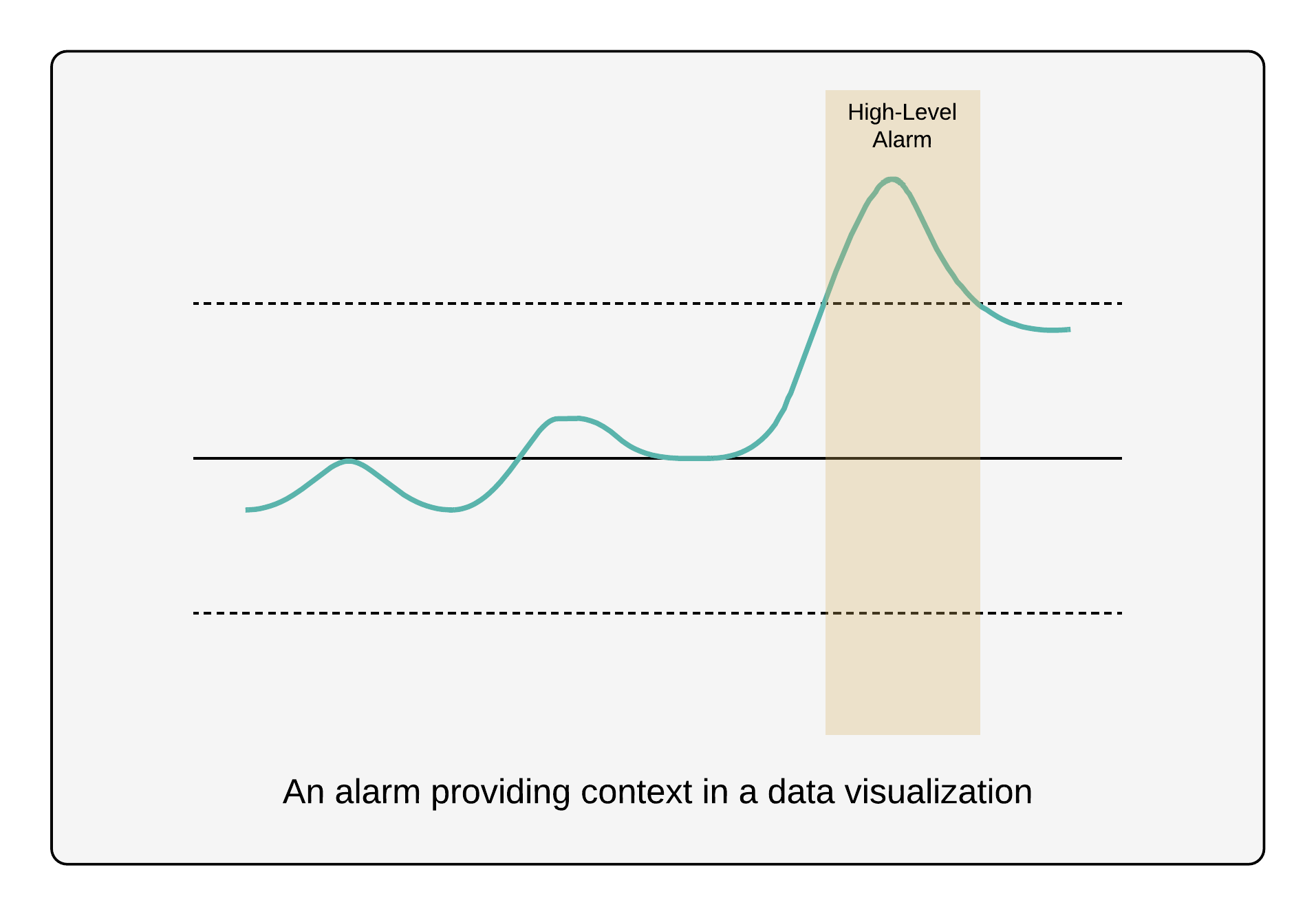
An individual device or process may have tens or hundreds of alarms and events. Some may reflect industry standards, but most are specific to a particular device or vendor. While an individual alarm or event is binary, there can be multiple alarms and events active at the same time and they need to be composed in order to understand the current state of the system. For example, the fluid level in a tank may be high, the outlet valve may be closed, and the inlet pump stopped; or a boiler may have a low-oxygen alarm, a low temperature control-limit excursion, while also operating in manual, rather than automatic. Alarms and events often imply a structural hierarchy used for organization and prioritization. For instance, an operator may want to understand that a tank is faulted, independent of it resulting from a high-pressure alarm or a low-pressure alarm, or may want to deal with a substation trip with a higher priority than a single malfunctioning inverter.
Relying on strings to represent this kind of complex information will break down at some point. If there are five alarms active, should they be concatenated into a single string? Perhaps with each state separated by an artistic double dash? Representing hierarchy, topology, or schema in the string devolves into the creative use of prefixes, suffixes, and formatting, like prefixing aggregate alarms and events with AGGREGATE, or top level alarms and events with LEVEL_1. Strings are wonderfully flexible, but this flexibility becomes a huge problem when someone casually changes the casing, the formatting, or the meaning of a string. Even if structured somewhat sensibly into a JSON document, the strings themselves are ultimately a poor and brittle contract.
Constraints Liberate, Liberties Constrain
—Rúnar Bjarnason
Bit Fields
Industrial software typically uses a single bit to represent the binary state of an alarm or an event, often directly reflecting the device register.[2] This convention is used widely in microcontrollers, programmable logic controllers (PLCs), supervisory control and data acquisition (SCADA), distributed control systems (DCS), and industry-standard protocols for interprocess communication.
A set of binary states can be atomically represented in a bit field.[3] For example, the fact that a tank has a high-level alarm, an outlet value that is closed, and an inlet pump that is off might be represented with the first, third, and seventh bits in the following 8-bit binary representation: 0b01000101. The equivalent representation in hexadecimal is 0x45 and decimal is 69.
A bit field representation has many advantages for data collection, representation, and query. A bit field is more compact and efficient to transmit than the equivalent string representation which can reduce messaging costs from IoT devices publishing telemetry to the cloud, especially over cellular or low-bandwidth networks. In addition, because it takes less space, the same devices can buffer more data locally when they are network partitioned from the cloud.
Often ignored, a bit field is also more efficient to store and query in the cloud. Consider a system that has 100 or more alarms and events. If the alarms and events are stored in a denormalized fashion in a columnar or time-series database, querying for the current state of all alarms will result in making over 100 reads, one for each denormalized signal. As the device reports new measurements, these values will also change over time, so there is no way to atomically query the current state. Contrast this with simply storing the bit field where a single query for the last value will represent all alarms and events, atomically and holistically, eliminating race conditions. If a query is only interested in a subset of alarms or events, the equivalent of querying specific columns in a columnar or time-series database, the bit field can be masked with the states of interest.
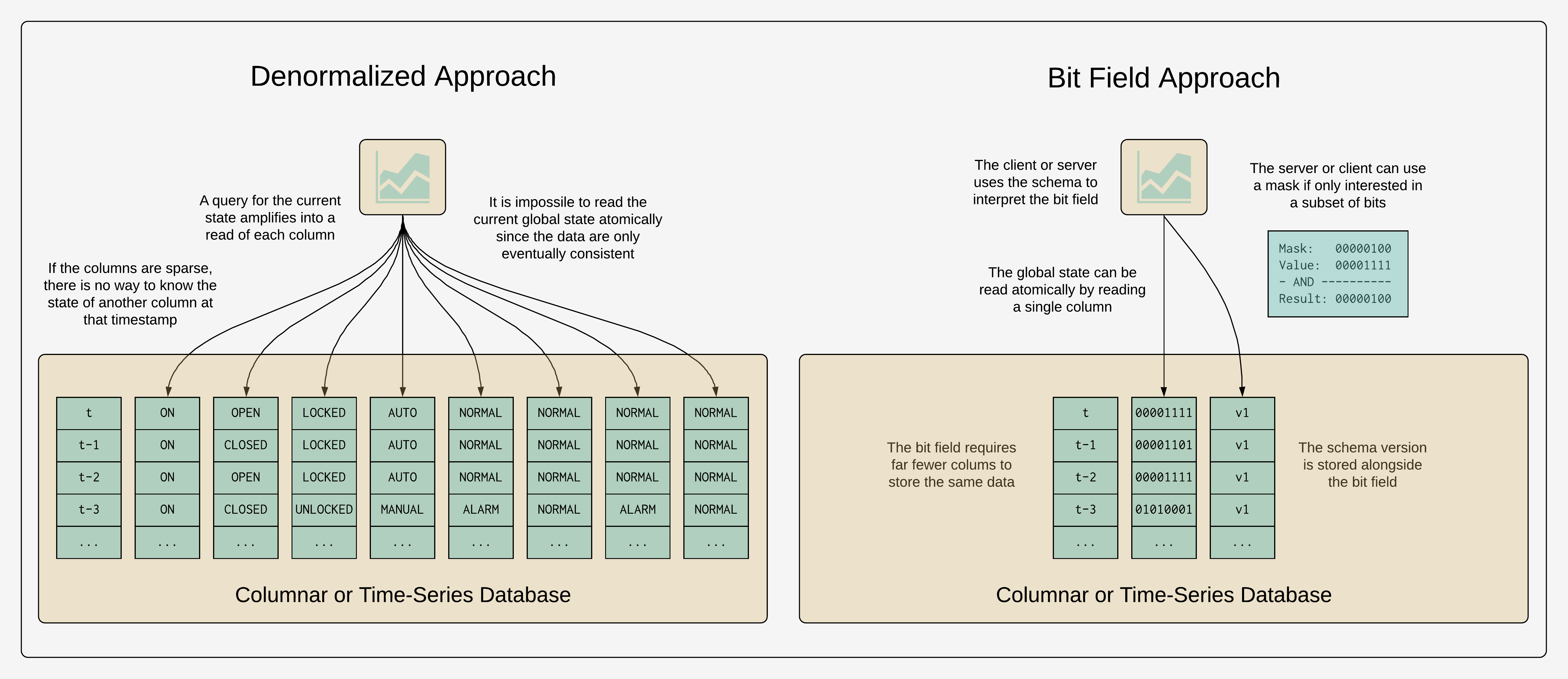
Systems typically communicate alarms and events on change, as well as on a periodic basis, like once every hour. Reporting the global state of alarms and events through a bit field, rather than a sparse representation of each individual alarm or event, means that each time the state is reported, the observer has a consistent view of the entire state. Even if individual transitions or messages are missed, the state will eventually converge. This is an important and often underappreciated messaging pattern in message-based, eventually-consistent systems, especially ones used in operational technologies.[4] Reporting the global state with each update means that simply looking at the last value allows one to understand the complete representation of all alarms and events, without querying or joining with any other series.
Challenges
Representing complex state in a bit field is not without challenges. Using the binary string or integer alone is not helpful. For example, the integer 0x00000104 has two bits set representing a process operating in Manual Override mode in combination with a High Level alarm. In decimal this value is 260. Displaying the 260 on a graph or in a table does not communicate much information. The operator, analyst, or engineer wants to see the text that indicates that the process is in Manual Override event and High Level alarm. Most tools do not support representing complex state in human digestible formats and it makes it hard to incorporate the use of bit field representations into generic open-source tooling without the support of data transformations.
Anything that uses the raw bytes—a graphical application, a database, or a tool for big-data analysis—needs to be able to interpret them and needs a library that can translate the individual bits into a human readable string. This makes schema management a central problem. Just like we have seen evolve with gRPC, we need similar ways to evolve schema, lint, test, discover, share, and ensuring backwards compatibility. Managing and evolving schema also makes the barrier to change much higher than just changing a string, which is partly the point.
I have seen SCADA systems where the meaning of the bits in a bit field change over time. Often these systems are installed as projects and the software is adapted to meet the individual requirements of each customer. This makes systems very hard to maintain. Recently, I have seen a lot of success from maintaining bit field schemas in source control and developing shared libraries from them. The bit field schemas are described in a JSON document which identifies the bit, the string associated with the bit, for use in visualizations, and even metadata like alarm priority. The string representation can be modified, or even localized, without the burdensome need to modify historical data stored in a columnar of time-series database.[5] Bits in the schema can be modified in an additive manner, but if the interpretation of the bits is revised, a new version of the schema must be created.
Conclusion
Strings are flexible and self-describing. It can be tempting to use them to represent complex state. At scale, however, this flexibility introduces huge problems, making systems brittle, hard to test, and difficult to evolve, especially when integrated into operational technologies or customer-facing services, as opposed to internal platforms strictly focused on the generic analysis of big data. At scale, strings are also expensive to process and store, especially when they are denormalized, and they can also lead to issues with atomicity and eventual consistency that can have serious operational consequences.
Industrial software systems have always favoured dense representations of information for efficiency, specificity, and atomicity. Cloud computing and IoT have introduced new tools that allow us to build services and applications that we never could have before, however, we should be concerned with the computing power currently used to process and store loads of strings. In the age of ubiquitous computing and IoT, we need a renewed focus on dense and efficient representations of information. Maybe the industrial world had it right all along.
Cynically, as long as the revenue generated from the advertisements you click on, or from selling insights into your personal data, is more significant than the excessive computing costs, more is more, at least for the largest web properties. ↩︎
While it may seem more natural to represent an alarm or an event using an enumeration, enumerations do not compose well when many alarms or events can be active at the same time and end up ballooning into an unworkable number of states. ↩︎
In multi-threaded programs, bit fields can be manipulated in a thread-safe manner, without using locks, using atomic processor-instructions. For an example, see The Most Difficult Bug I Have Encountered. ↩︎
Reporting the global state periodically, like once an hour, also means that one does not need to look back in time indefinitely to find the last state, which can be a very inefficient query in time-series database. Instead, the query can be bounded by the expected reporting interval. ↩︎
An excellent example of a strong schema and a strict contract creating a liberating flexibility. ↩︎