Kubernetes Liveness and Readiness Probes: Looking for More Feet
I expand on these ideas in my presentation Kubernetes Probes: How to Avoid Shooting Yourself in the Foot.
Kubernetes liveness and readiness probes are mechanisms to improve service reliability and availability. For example, if a container is unresponsive, restarting the container can make the application more available, despite the defect. I have written two articles on how these mechanisms, designed to improve system reliability and availability, can make it worse, through unintended consequences.
The first article focused on the basics of liveness and readiness probes. I detailed how significant outages can occur if you do not realize that the readiness probe will continue to be called throughout the lifetime of the pod, not just at startup, or if the readiness probe checks a common dependency shared among all pods. I also detailed how outages can occur if the liveness probe does not exercise the service in a similar manner to client requests, or if the liveness probe is too aggressive and the service can never be restarted. My recommendations were to consider the full array of system dynamics when implementing liveness and readiness probes and to avoid being overly aggressive.
The second article expanded on these examples and showed how individual pods backing a service can slowly become unavailable, and never recover, if a readiness probe is implemented without an accompanying liveness probe. I also explored what an error is and I highlighted the problems that can occur if the programmer attempts to handle errors, rather than simply crashing and letting Kubernetes restart the container.
In this article, the final one in this three-part series, I will examine problems that can occur with liveness and readiness probes when services do not have sufficient isolation. Continuing the theme from the previous two articles, without sufficient isolation, liveness and readiness probes can make service availability and reliability worse, rather than better.
Services with Diverse Queries
An example that I presented in my first article was a readiness probe that evaluates a set of shared dependencies. The readinessProbe method, which is called from the /readiness route below, evaluates three dependencies as part of the probe: 1) a service for authorization requests, 2) a service for inventory requests, and 3) a service for telemetry requests.
trait ServerWithDependenciesProbeRoutes {
implicit def ec: ExecutionContext
def httpClient: HttpRequest => Future[HttpResponse]
private def httpReadinessRequest(
uri: Uri,
f: HttpRequest => Future[HttpResponse] = httpClient): Future[HttpResponse] = {
f(HttpRequest(method = HttpMethods.HEAD, uri = uri))
}
private def checkStatusCode(response: Try[HttpResponse]): Try[Unit] = {
response match {
case Success(x) if x.status == StatusCodes.OK => Success(())
case Success(x) if x.status != StatusCodes.OK => Failure(HttpStatusCodeException(x.status))
case Failure(ex) => Failure(HttpClientException(ex))
}
}
private def readinessProbe() = {
val authorizationCheck = httpReadinessRequest("https://authorization.service").transform(checkStatusCode)
val inventoryCheck = httpReadinessRequest("https://inventory.service").transform(checkStatusCode)
val telemetryCheck = httpReadinessRequest("https://telemetry.service").transform(checkStatusCode)
val result = for {
authorizationResult <- authorizationCheck
inventoryResult <- inventoryCheck
telemetryResult <- telemetryCheck
} yield (authorizationResult, inventoryResult, telemetryResult)
result
}
val probeRoutes: Route = path("readiness") {
get {
onComplete(readinessProbe()) {
case Success(_) => complete(StatusCodes.OK)
case Failure(_) => complete(StatusCodes.ServiceUnavailable)
}
}
}
}
I noted that if the readiness probe is not forgiving enough, a small, temporary increase in latency to one of the shared dependencies can make the entire service unavailable, because the readiness probe will fail on all pods at the same time and Kubernetes will not route traffic to any of the pods.
For a service with a number of dependencies and a diverse set of queries, not all queries may exercise each dependency. Using the example above, perhaps all queries rely on the services for authorization and inventory, but only a small fraction of queries exercise the dependency on the telemetry service. If we were to fail the readiness probe when only the telemetry service was unavailable, the entire service would become unavailable and all requests would fail, even though it would still be able to satisfy the majority of the requests that do not involve the telemetry service.
As we are breaking larger services into smaller and more specialized services, it can be advantageous to decompose services into more discrete units of failure, to provide stronger isolation. If the majority of queries do not rely on the telemetry service, then isolate these routes in another service that does not have a dependency on the telemetry service, and, therefore, does not evaluate it in its readiness probe.
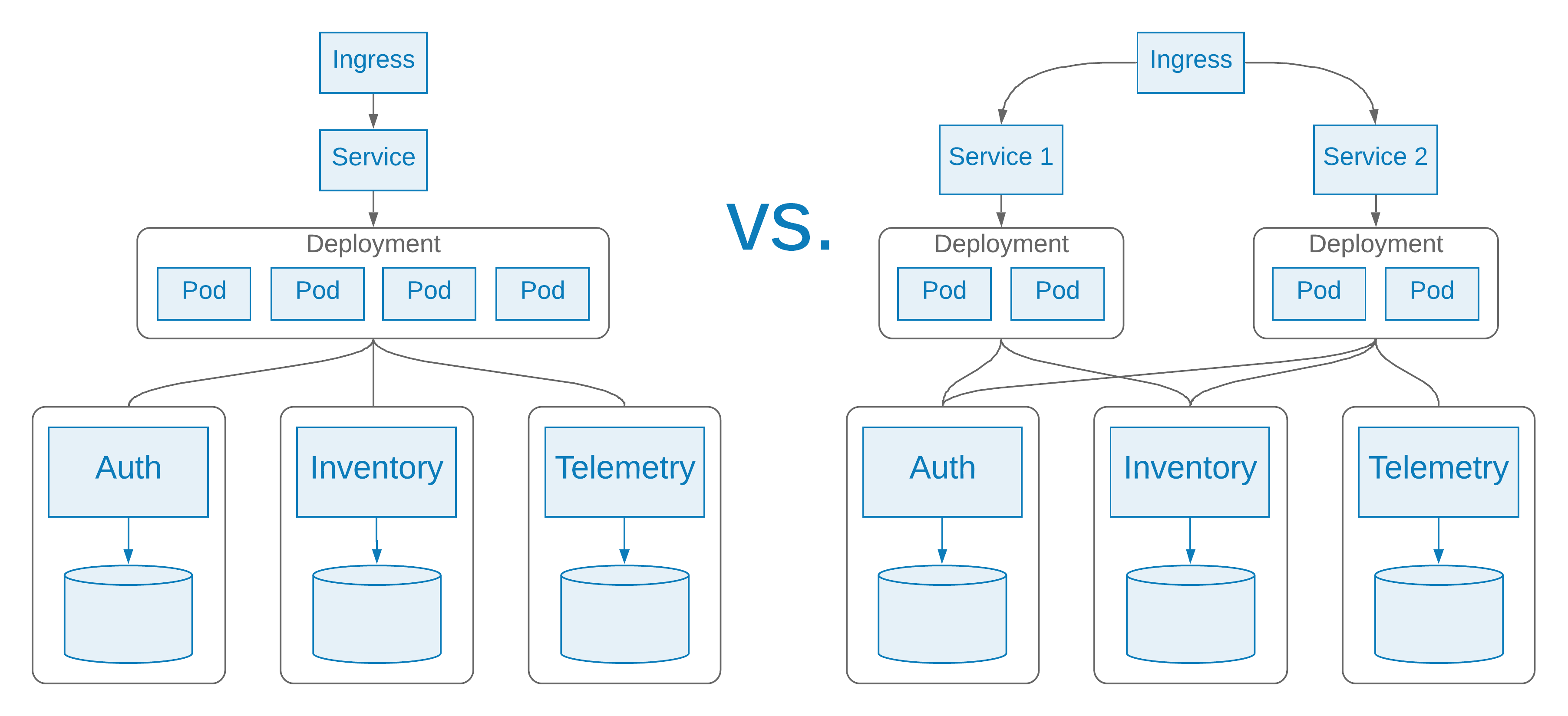
There is more overhead in maintaining services in this manner, but encapsulating services along unique failure domains can lead to much more reliable services. One of the real strengths of containers and Kubernetes is the flexibility it provides for managing a large number of services. Even though the underlying source code and containers might be the same in this case, we can define one service and deployment for handling the requests that involve telemetry, and an independent service, with an independent deployment, for handling the other routes. The two services can have readiness probes dedicated to their respective dependencies.
Ingress Reloads and Long-Lived Connections
A Kubernetes ingress exposes routes from outside the cluster to services within the cluster. A very popular Kubernetes ingress controller is Nginx. Although there are a number of controllers available, at the time of this writing, Nginx is one of only two controllers that the Kubernetes project supports and maintains.
When services change—a new service is deployed, or an old service is deleted—Nginx must reload its configuration to reflect these changes. Nginx must also reload its configuration to reflect changes in service availability as a result of readiness probes succeeding or failing.
Continuing the example from my previous article, when all of the pods in the cache service fail the readiness probe, the service becomes unavailable and Nginx must reload its configuration. The Nginx logs will report something like the following:
W0106 18:30:00.908975 6 controller.go:806] Service "default/cache-server-svc" does not have any active Endpoint. I0106 18:30:00.910760 6 controller.go:171] Configuration changes detected, backend reload required. I0106 18:30:01.020226 6 controller.go:187] Backend successfully reloaded. I0106 18:30:01.024728 6 controller.go:204] Dynamic reconfiguration succeeded.
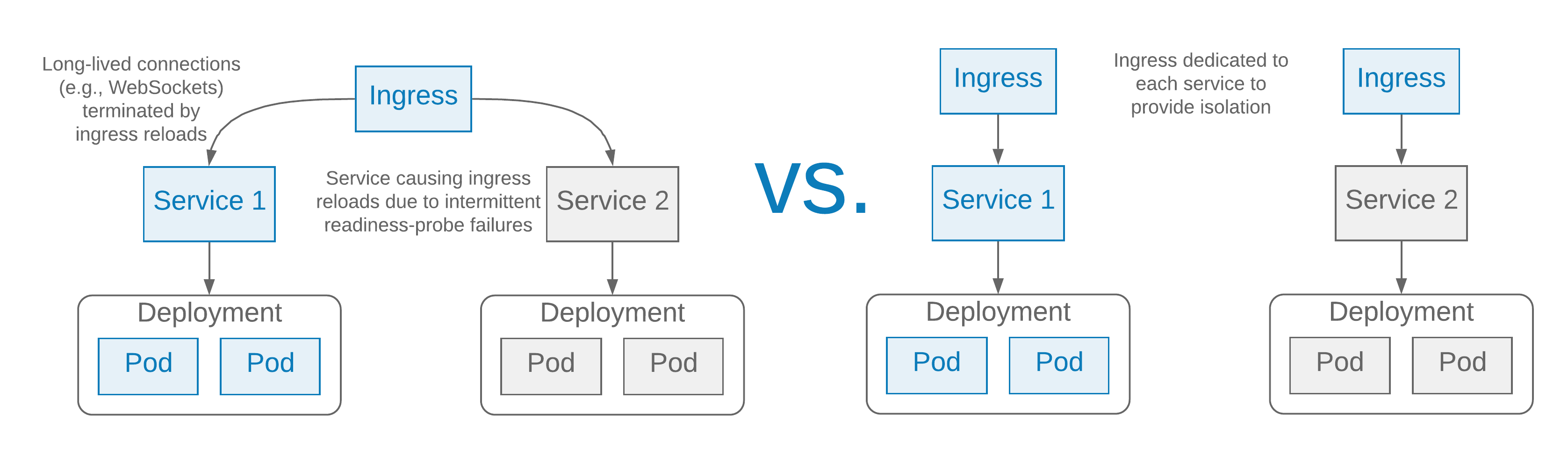
It is not uncommon for an ingress controller to be a cluster-wide resource, shared across a number of services, or even namespaces. Consider what happens if all pods in a service are intermittently failing readiness probes. The Nginx ingress controller will need to regularly reload its configuration. This may not have a big impact on short-lived HTTP requests, but if the ingress controller is also handling long-lived connections, like WebSockets or Server Sent Events, the continuous Nginx reloads will result in continuously terminating these long-lived connections, which can be very disruptive, and lead to a poor customer experience. Interestingly, the service that is intermittently failing the readiness probes may not even be a critical service—perhaps it is a canary deployment as part of commissioning a new service—and, in a multi-tenant cluster, it may not even be in the same namespace as the service with the affected long-lived connections.
There are ways to avoid Nginx reloads impacting service availability. One way is to set the Nginx worker_shutdown_timeout parameter longer than the default of 10 seconds, by adding the nginx.ingress.kubernetes.io/worker-shutdown-timeout annotation to the ingress configuration. This setting controls how long Nginx will wait before closing active connections and shutting down a worker process, which happens when backends are reloaded after configuration changes. When an HTTP request, like a typical GET request, can take longer than 10 seconds to complete, adjusting this setting can make Nginx reloads less disruptive and improve service availability. But for long-lived connections, like WebSockets or Server Sent Events, which are expected to last for hours, or even days, this setting does not provide a workable solution. If set to something like 24 hours, Nginx will accumulate workers, using more and more memory, until it is exhausted. Another option is to use the commercial version of the Nginx ingress controller, which supports dynamic reloading.
Rather than attempting to avoid reloads, however, it is better to dedicate an ingress controller to each namespace in a multi-tenant Kubernetes cluster, or even dedicate an ingress controller to a single service. This can be done by configuring the Nginx ingress controller deployments to use named ingress-classes, using the Nginx --ingress-class argument, and associating the ingress configurations with these ingress classes using the kubernetes.io/ingress.class annotation. This improves isolation and means that, among other things, unreliable services that regularly oscillate between being available and unavailable, through the readiness probe mechanism, cannot impact other services, especially ones with long-lived connections.
Summary
Since liveness and readiness probes hold the promise of improved reliability and they are easy mechanisms to implement, often through configuration alone, people regularly add liveness and readiness probes and accept the defaults, without considering the full implications. I hope the examples that I have provided in this series help you avoid shooting yourself in the foot with liveness and readiness probes and ultimately build more reliable services running on Kubernetes. The examples I provided might seem contrived or simplistic at times, but I have seen all of these situations play out as people adopt Kubernetes probes without fully understanding their implications, or adding them to services for which they do not yet have a complete understanding of the system dynamics and error conditions.
On the surface, Kubernetes liveness and readiness probes are very simple mechanisms designed to improve the reliability of services. However, we cannot forget the second point from Lorin's Conjecture, that I referenced in my previous two articles:
Once a system reaches a certain level of reliability, most major incidents will involve the unexpected behaviour of a subsystem whose primary purpose was to improve reliability.
As I have demonstrated in this series, if Kubernetes liveness and readiness probes are not used carefully, they can end up making service reliability significantly worse, rather than better.