Integrating Akka Streams and Akka Actors: Part III
I expand on these concepts in my Reactive Summit presentation.
In the first article of this series, I described the basic patterns for interfacing the Akka Streams API and Akka Actors. In the second article, I focused on how Akka Actors compliment the Akka Streams API with regard to the fault tolerance and life-cycle management of a stream. In this article, I will continue to explore patterns for integrating the Akka Streams API with Akka Actors, in support of building scalable and resilient systems for streaming data. I will demonstrate how to run streaming workloads in an Akka Cluster in a distributed, scalable, and fault-tolerant manner, by leveraging Cluster Sharding and Distributed Data. I will also explore how Akka Actors can be used to provide location transparency for the Akka Streams API.
Distributed Stream Processing
Building on the wind-turbine-simulator example that I developed in the previous article in this series, consider simulating hundreds-of-thousands, or even millions, of wind turbines, more than can be supported by the resources of a single server. At the time of this writing, the Akka Streams API does not have a native way to distribute workloads in a cluster, or offer location transparency for streams. Actors, however, provide location transparency and support a number of models for distributing workloads within a cluster. The Akka Streams API can be combined with Akka Actors, therefore, to distribute workloads in powerful ways.
To demonstrate, contemplate simulating one-hundred thousand wind-turbines in order to test the measurement collection and aggregation service at scale. Each wind-turbine simulator maintains a WebSocket connection for sending telemetry to the service, once a second. The example that I presented in the previous article can be extended to distribute a unique actor for every simulated wind-turbine, uniformly, across an Akka cluster, using Cluster Sharding. The first step to accomplishing this is to host the wind-turbine-simulator actor, and its associated backoff-supervisor actor, in a wind-turbine-supervisor actor.
object WindTurbineSupervisor {
final case object StartSimulator
final case class StartClient(id: String)
def props(implicit materializer: ActorMaterializer) =
Props(classOf[WindTurbineSupervisor], materializer)
}
class WindTurbineSupervisor(implicit materializer: ActorMaterializer) extends Actor {
override def preStart(): Unit = {
self ! StartClient(self.path.name)
}
def receive: Receive = {
case StartClient(id) =>
val supervisor = BackoffSupervisor.props(
Backoff.onFailure(
WindTurbineSimulator.props(id, Config.endpoint),
childName = id,
minBackoff = 1.second,
maxBackoff = 30.seconds,
randomFactor = 0.2
)
)
context.actorOf(supervisor, name = s"$id-backoff-supervisor")
context.become(running)
}
def running: Receive = Actor.emptyBehavior
}
The following program uses a clustered actor-system and hosts a shard-region for the wind-turbine-supervisor actors. This means that this application is capable of running WindTurbineSupervisor actors that are part of the shard-regions assigned to this host.
object WindTurbineClusterShards extends App {
val port = args(0)
val config = ConfigFactory.parseString(s"akka.remote.netty.tcp.port=$port")
.withFallback(ConfigFactory.parseString("akka.cluster.roles = [WindTurbineSimulator]"))
.withFallback(ConfigFactory.load())
implicit val system = ActorSystem.create("ClusterActorSystem", config)
implicit val materializer = ActorMaterializer()
val windTurbineShardRegion = ClusterSharding(system).start(
typeName = "WindTurbineSupervisorShardRegion",
entityProps = WindTurbineSupervisor.props,
settings = ClusterShardingSettings(system),
extractEntityId = WindTurbineClusterConfig.extractEntityId,
extractShardId = WindTurbineClusterConfig.extractShardId
)
sys.addShutdownHook {
Await.result(system.whenTerminated, Duration.Inf)
}
}
The sharding configuration is defined as follows, sharding the WindTurbineSupervisor actors uniformly across the cluster, based on the unique identifier of the wind turbine. The shard is determined by the extractShardId member, using the identifier in the EntityEnvelope message. When using the remember entities feature to restart the shard region and its associated actors after a cluster rebalance, or a restart after a failure, the extractShardId member must also handle the ShardRegion.StartEntity message. The extractEntityId member is used for sending messages to the sharded actor, in this case, simply forwarding all messages via the payload parameter.
object WindTurbineClusterConfig {
private val numberOfShards = 100
val extractEntityId: ShardRegion.ExtractEntityId = {
case EntityEnvelope(id, payload) => (id, payload)
}
val extractShardId: ShardRegion.ExtractShardId = {
case EntityEnvelope(id, _) => (id.hashCode % numberOfShards).toString
case ShardRegion.StartEntity(id) => (id.hashCode % numberOfShards).toString
}
}
Observe that no changes are required to the WindTurbineSimulator actor—detailed in the previous article in this series—in order to distribute work evenly across an Akka cluster. The only thing that is necessary is the addition of one more layer of indirection, through the shard-region actor, without any changes to the business logic in the WindTurbineSimulator actor itself. This is similar to when I introduced the backoff supervisor in the previous article in this series.
Since this actor system is now running in an Akka cluster, there are some additional mechanisms involved, but, logically, the actor supervision-hierarchy can be represented as follows.
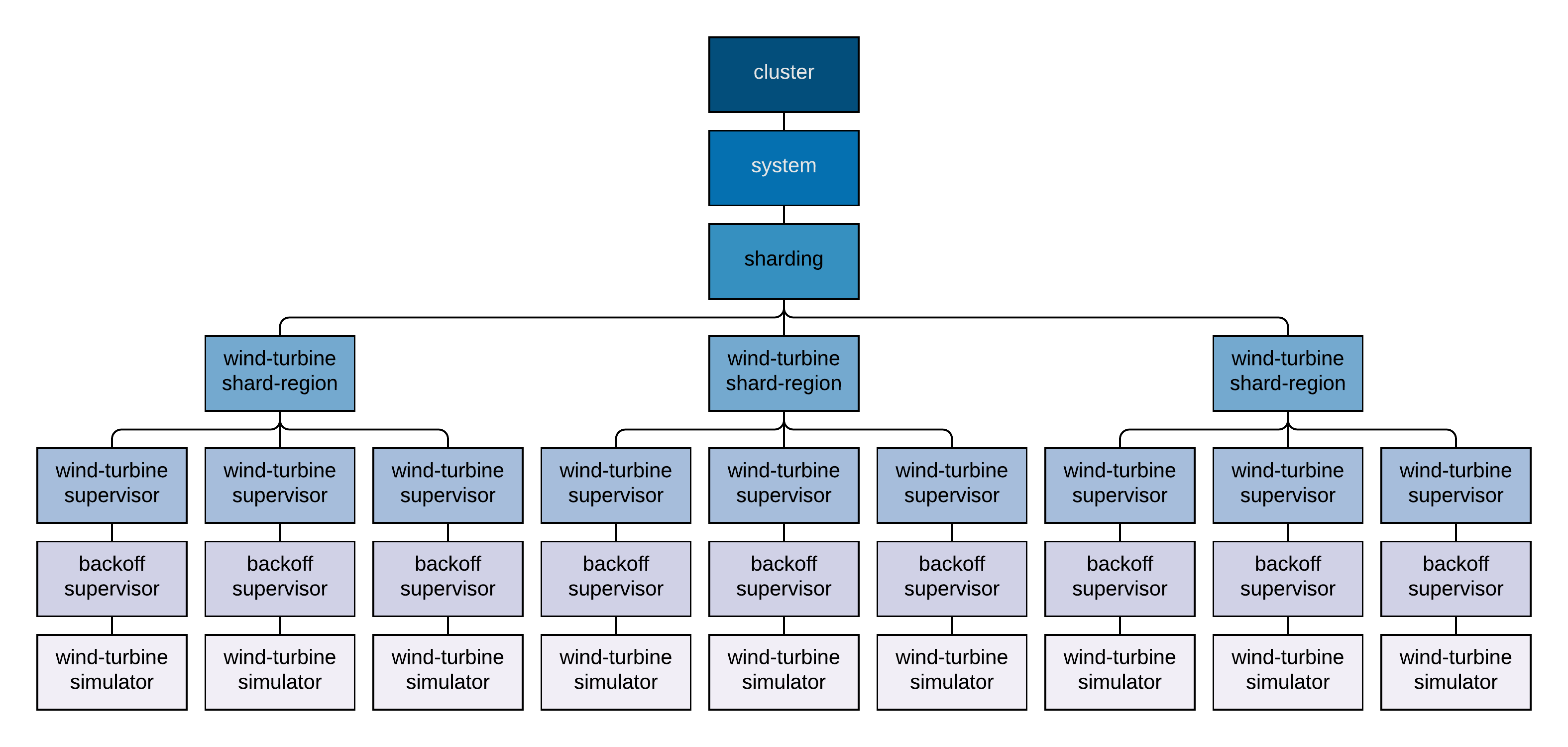
Note that every wind-turbine-shard-region actor is unique, supervising only the unique shards within the shard-region for which it is responsible. The wind-turbine-supervisor, backoff-supervisor, and wind-turbine-simulator actor-hierarchy is also unique, with only one wind-turbine-supervisor, and, therefore, wind-turbine-simulator actor, running in the cluster, per unique wind-turbine identifier. Also note that since these actors are managed by the cluster actor-system, they are under the system guardian-actor, rather than the user guardian-actor, like the actors in the previous article in this series.
To start the wind-turbine-simulator actors across the cluster, I will use a Cluster Sharding proxy, sending it a StartSimulator message. Note that in this case, the message sent to the actor is immaterial—it could be any message—since the wind-turbine-supervisor actor sends itself a StartClient message in the preStart method for initialization.
object WindTurbineProxy extends App {
val port = args(0)
val config = ConfigFactory.parseString(s"akka.remote.netty.tcp.port=$port")
.withFallback(ConfigFactory.parseString("akka.cluster.roles = [WindTurbineProxy]"))
.withFallback(ConfigFactory.load())
implicit val system = ActorSystem.create("ClusterActorSystem", config)
implicit val materializer = ActorMaterializer()
implicit val executionContext = system.dispatcher
val windTurbineShardRegionProxy: ActorRef = ClusterSharding(system).startProxy(
typeName = "WindTurbineSupervisorShardRegion",
role = None,
extractEntityId = WindTurbineClusterConfig.extractEntityId,
extractShardId = WindTurbineClusterConfig.extractShardId
)
Source(1 to 100000)
.throttle(
elements = 100,
per = 1 second,
maximumBurst = 100,
mode = ThrottleMode.shaping
)
.map { _ =>
val id = java.util.UUID.randomUUID.toString
windTurbineShardRegionProxy ! EntityEnvelope(id, StartSimulator)
}
.runWith(Sink.ignore)
sys.addShutdownHook {
Await.result(system.whenTerminated, Duration.Inf)
}
}
The Cluster Sharding proxy will not host any shard-region actors directly, rather, it will proxy messages to the associated wind-turbine-shard-region actor within the cluster, responsible for the shard. The actor supervision-hierarchy for the application that starts all of the wind-turbine simulators, through the Cluster Sharding proxy, is the following.
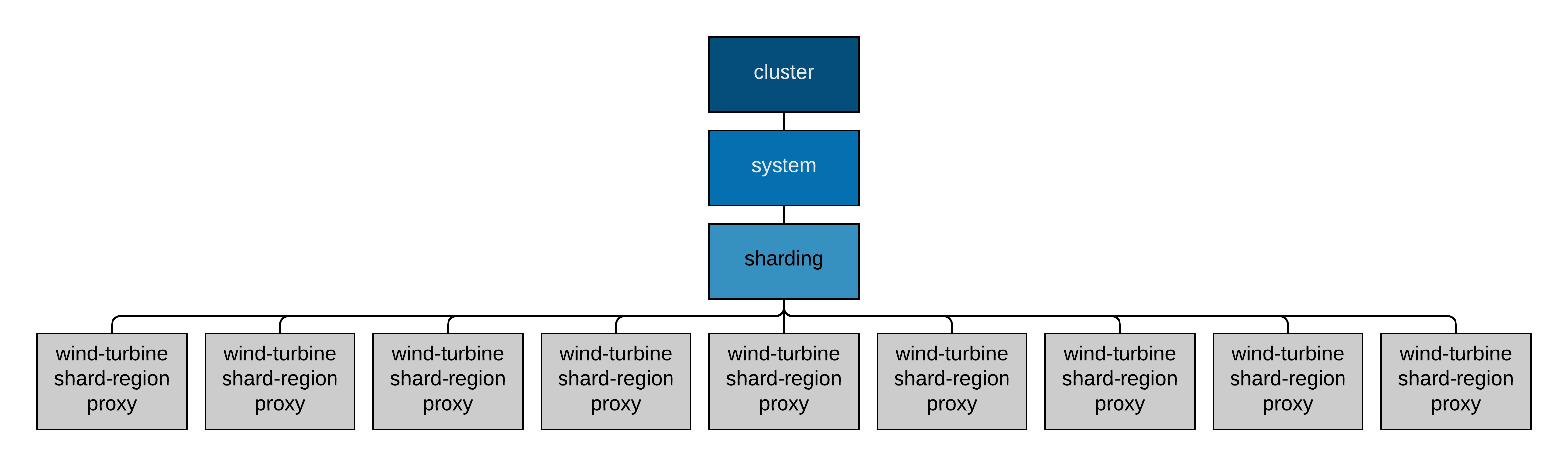
In order to run all of the wind-turbine actors simulating the real-time telemetry, consider the following four-node Akka cluster. Three nodes in the cluster will assume the wind-turbine-simulator role and run the unique wind-turbine shard-regions, and wind-turbine-simulator actors, represented by the actor hierarchy presented previously. The fourth node in the cluster simply uses the shard-region proxy, represented by the actor hierarchy just presented, to start all of the wind-turbine-simulator actors.
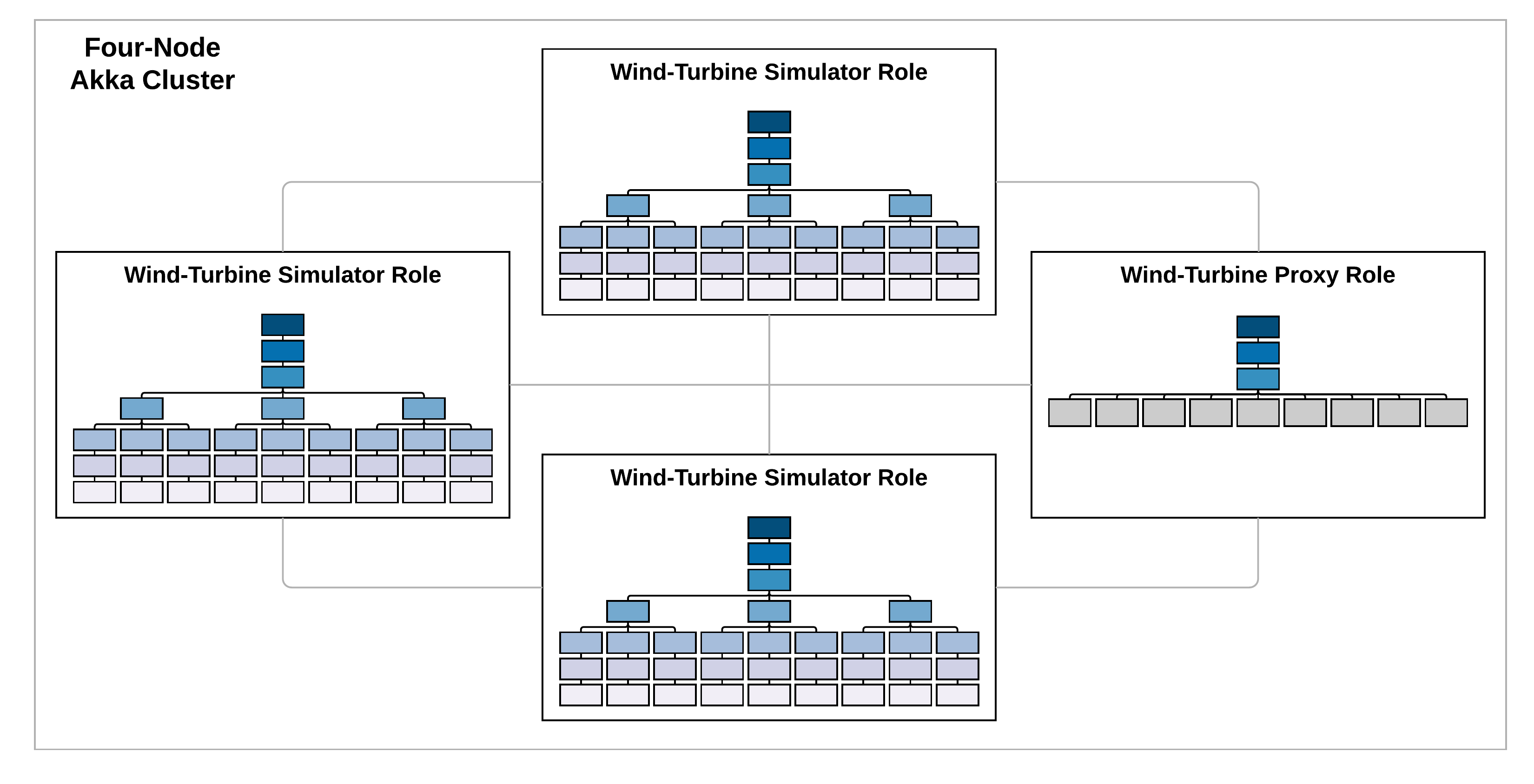
The application.conf configuration file for the clustered actor-systems is below. Since all that is required to restart the wind-turbine-simulator actor is the unique identifier in the name of the actor, Distributed Data (state-store-mode = ddata) is sufficient for persistence (maintaining more complex state would require a persistent actor, using Akka Persistence). In addition, remember-entities = on is used so that whenever a shard is rebalanced onto another node, or recovers after a failure, it will recreate all of the actors that were previously running in that shard. Note that this configuration uses 127.0.0.1 as the host, and ports that do not conflict, so that you can test this configuration running locally.
akka {
actor {
provider = "akka.cluster.ClusterActorRefProvider"
}
remote {
enabled-transports = ["akka.remote.netty.tcp"]
netty.tcp {
hostname = "127.0.0.1"
port = "2550"
}
}
cluster {
seed-nodes = [
"akka.tcp://ClusterActorSystem@127.0.0.1:2551",
"akka.tcp://ClusterActorSystem@127.0.0.1:2552"
]
// Needed to move the cluster-shard to another node
// Do not in production
auto-down-unreachable-after = 3s
sharding {
role = "WindTurbineSimulator"
state-store-mode = ddata
remember-entities = on
}
}
}
If servers are added to, or removed from, the cluster, the wind-turbine-supervisor actors will be automatically rebalanced, or restarted, respectively, to keep the shards evenly distributed across the cluster. If a node in the cluster becomes temporarily, or permanently, unavailable, the wind-turbine simulators running on the node that is inaccessible will be restarted on another node in the cluster. These dynamics are hard to represent here, but they are extremely impressive, and immensely satisfying to see in action. Implementing this functionality without the Akka toolkit would require an enormous investment in design, development, and testing.
Location Transparency
In addition to distributing workloads across a cluster, the cluster shard-region also provides location transparency. This means that a message can be sent to the actor supervising a specific wind-turbine-simulator actor, without having to know which server it is currently running on in the cluster.
As a simplistic example, the wind-turbine-supervisor actor can be extended to forward messages to its child wind-turbine-simulator actor, through the backoff supervisor.
class WindTurbineSupervisor(implicit materializer: ActorMaterializer) extends Actor {
override def preStart(): Unit = {
self ! StartClient(self.path.name)
}
def receive: Receive = {
case StartClient(id) =>
val supervisor = BackoffSupervisor.props(
Backoff.onFailure(
WindTurbineSimulator.props(id, Config.endpoint),
childName = id,
minBackoff = 1.second,
maxBackoff = 30.seconds,
randomFactor = 0.2
)
)
context.become(
running(
context.actorOf(supervisor, name = s"$id-backoff-supervisor")
)
)
}
def running(child: ActorRef): Receive = {
case message => child forward message
}
}
If the wind-turbine-simulator actor is sent a QueryActorPath message, it will respond with its actor path.
object WindTurbineSimulator {
def props(id: String, endpoint: String)(implicit materializer: ActorMaterializer) =
Props(classOf[WindTurbineSimulator], id, endpoint, materializer)
final case object Upgraded
final case object Connected
final case object Terminated
final case object QueryActorPath
final case class ConnectionFailure(ex: Throwable)
final case class FailedUpgrade(statusCode: StatusCode)
final case class SimulatorActorPath(path: String)
}
class WindTurbineSimulator(id: String, endpoint: String)
(implicit materializer: ActorMaterializer)
extends Actor with ActorLogging {
implicit private val system = context.system
implicit private val executionContext = system.dispatcher
val webSocket = WebSocketClient(id, endpoint, self)
override def postStop() = {
log.info(s"$id : Stopping WebSocket connection")
webSocket.killSwitch.shutdown()
}
override def receive: Receive = {
case Upgraded =>
log.info(s"$id : WebSocket upgraded")
case FailedUpgrade(statusCode) =>
log.error(s"$id : Failed to upgrade WebSocket connection : $statusCode")
throw WindTurbineSimulatorException(id)
case ConnectionFailure(ex) =>
log.error(s"$id : Failed to establish WebSocket connection $ex")
throw WindTurbineSimulatorException(id)
case Connected =>
log.info(s"$id : WebSocket connected")
context.become(running)
}
def running: Receive = {
case QueryActorPath =>
sender ! SimulatorActorPath(context.self.path.toString)
case Terminated =>
log.error(s"$id : WebSocket connection terminated")
throw WindTurbineSimulatorException(id)
}
}
The wind-turbine-simulator actor can be queried as follows, through the cluster shard-region proxy.
import akka.pattern.ask implicit val askTimeout = Timeout(30 seconds) val id = "6c84fb90-12c4-11e1-840d-7b25c5ee775a" (windTurbineShardRegionProxy ? EntityEnvelope(id, QueryActorPath)) .mapTo[SimulatorActorPath] .map(response => println(s"$response"))
This is a basic example, but this approach could be combined with some of the techniques that I presented in the first article in this series, to interface actor-messaging with streams, in order to report the current state of each wind-turbine simulator; collect metrics on the number of messages sent to the service; or inject messages into the stream, perhaps to test failure conditions, during the simulation.
A Few Words of Caution
Before concluding this article, a few words of caution. In the examples that I have provided, I was using automatic-downing of nodes in the cluster, since it was easy to use for testing this basic example. Automatic downing should not be used in production, however, since it can lead to split-brain scenarios within the cluster, which can be problematic, especially when used in combination with Cluster Sharding. In addition, I also used the default Java serialization for sending the EntityEnvelope messages to the cluster shard-region, since Java serialization works without additional configuration. Java serialization, however, has poor performance and a large footprint. For a production system, one should use a different serialization format, like Protocol Buffers. See the Akka documentation for further discussion on both of these topics.
Looking Forward
In this article, I extended the wind-turbine simulator example from the previous article in this series, to show how Akka Actors can be used to distribute streaming workloads—workloads that use the Akka Stream API—within an Akka Cluster. By leveraging Akka Actors, this approach provides fault-tolerance, location transparency, and scalability for the Akka Streams API.
At the time of this writing, Akka does not support the distributed materialization of streams. This would be very powerful and it will be interesting to see if it ever becomes part of the Akka toolkit at some point. Distributed stream-processing technologies continue to evolve rapidly and it is unclear which technologies will emerge as the longer-term platforms in this field. For example, Lightbend, the company behind Akka, is promoting its Fast Data Platform, which includes Kafka Streams, Apache Spark, and Apache Flink, for stream processing, in addition to the Akka Streams API. Lightbend has also supported Apache Gearpump, a real-time, big-data streaming-engine built on top of Akka and the Akka Streams API. As the distributed stream-processing landscape continues to evolve, combining the Akka Streams API with Akka Actors, to provide bounded memory-constraints, fault tolerance, life-cycle management, and distributed computation, is a compelling solution for a number of applications, and it can be accomplished without having to rely on frameworks outside of the Akka ecosystem.
In the final article of this series, I will demonstrate how the Akka Streams API can be combined with Akka Persistence and the Event Sourcing model, as a final method for interfacing the Akka Streams API with Akka Actors, in support of constructing robust and scalable systems for streaming data.