Integrating Akka Streams and Akka Actors: Part IV
I expand on these concepts in my Reactive Summit presentation.
In the first article of this series, I demonstrated the most basic patterns for integrating Akka Actors and the Akka Streams API. In the second article, I began developing an example to show how actors compliment streams, providing fault-tolerance and life-cycle management. In the third article, I extended this example to demonstrate how actors can be used to distribute streaming workloads in an Akka cluster, as well as provide location transparency for streams. In this article, the final article of the series, I will blur the lines somewhat, as I finish exploring patterns for integrating Akka Actors and the Akka Streams API. I will show how a persistent actor can manage a streaming workload, by durably persisting events using the Event Sourcing model. Then I will provide examples for streaming the events persisted by this actor, using the Akka Streams API for location-transparency and flow control.
Persistent Actors and Event Sourcing
Event Sourcing is a technique where all changes to the state of an aggregate—an industrial asset, a customer, an order, an application—are persisted as an ordered sequence of events. An application follows the Event Sourcing model if the current state of the aggregate can be reconstructed by replaying all previous events, in order. Events are typically stored durably in a journal. Akka has support for a number of persistence journals, but Apache Cassandra is a popular choice given its read and write scalability.
To improve performance, most Event Sourcing implementations snapshot the state from time to time, to reduce the number of events that need to be replayed to reconstruct the current state. Even when storing snapshots, for some applications, retaining the complete event history, indefinitely, can yield tremendous business value—you may not be able to anticipate the valuable questions you might ask of this data in the future. In some industries, retaining the full history may be required for regulatory compliance. In situations where retaining the full history is not required, storing snapshots can reduce storage overhead, as all events prior to the latest snapshot can be discarded.
Akka's actor persistence embraces the Event Sourcing model and, as a result, provides an elegant and robust means for evolving the internal state of an actor. A stream of events can be represented as a persisted log of changes to the internal state of an actor. To demonstrate, consider the wind-turbine example that I used in the previous two articles in this series. Imagine that in order to support operations and maintenance, the wind turbine can be set to a temporary diagnostic mode, in which it will report high-resolution telemetry and diagnostic information to a monitoring service, over a WebSocket connection. Every diagnostic event has a unique identifier, so that it can be queried later.
The server that handles the WebSocket connection streams the messages to a unique, persistent actor associated with the diagnostic event. The WebSocket stream is implemented below.
val diagnosticWebSocket = (diagnosticEvent: ActorRef) =>
Flow[Message]
.collect {
case TextMessage.Strict(text) =>
Future.successful(text)
case TextMessage.Streamed(textStream) =>
textStream.runFold("")(_ + _)
.flatMap(Future.successful)
}
.mapAsync(1)(identity)
.mapAsync(4) { event =>
import akka.pattern.ask
implicit val askTimeout = Timeout(30 seconds)
diagnosticEvent ? Event(event)
}
.mapConcat(_ => Nil)
Every event is sent to the actor via an asynchronous message. Since this message is asynchronous, the WebsSocket stream uses a technique discussed in the first article of this series, where a mapAsync stage is combined with the actor ask-pattern to provide flow-control and bounded resource-usage.
The WebSocket route is implemented as follows. The unique, persistent actor associated with the diagnostic event is created as part of establishing the WebSocket connection.
val route =
path(uuidRegex) { id =>
get {
val ref = system.actorOf(DiagnosticEvent.props(id), id)
handleWebSocketMessages {
diagnosticWebSocket(ref)
.watchTermination() { (_, done) =>
done.map(_ => ref ! Stop)
}
}
}
}
val bindingFuture = Http().bindAndHandle(route, "0.0.0.0", 8080)
When the WebSocket connection is terminated, the actor will be sent a Stop message. Note this is a technique for integrating actors and streams that I have not yet discussed. The watchTermintaion method is used to manage the lifecycle of an actor, based on the lifecycle of a stream. When the stream completes, the actor will be stopped.
The persistent actor is named with the unique identifier of the diagnostic event. It also uses this identifier as the stable persistence-identifier, persistenceId. The persistent actor is implemented as follows.
class DiagnosticEvent(id: String) extends PersistentActor {
override def persistenceId: String = id
override def receiveRecover: Receive = Actor.emptyBehavior
override def receiveCommand: Receive = {
case event: Event =>
persist(event) { event =>
sender() ! Done
}
case Stop =>
context.stop(self)
}
}
The receiveCommand method is called whenever the actor receives a message. When a new event message is received, the actor invokes the persist method to asynchronously append the event to the journal. After the event has been persisted, the actor will respond to the sender, in this case the ask from the WebSocket stream, with a message indicating that it is done. Note that normally it is not safe to close over the sender() method or access actor state in a Future, but the persist method is special in that it will maintain the original sender() reference, and it is safe to access and modify actor state from within the persist method.
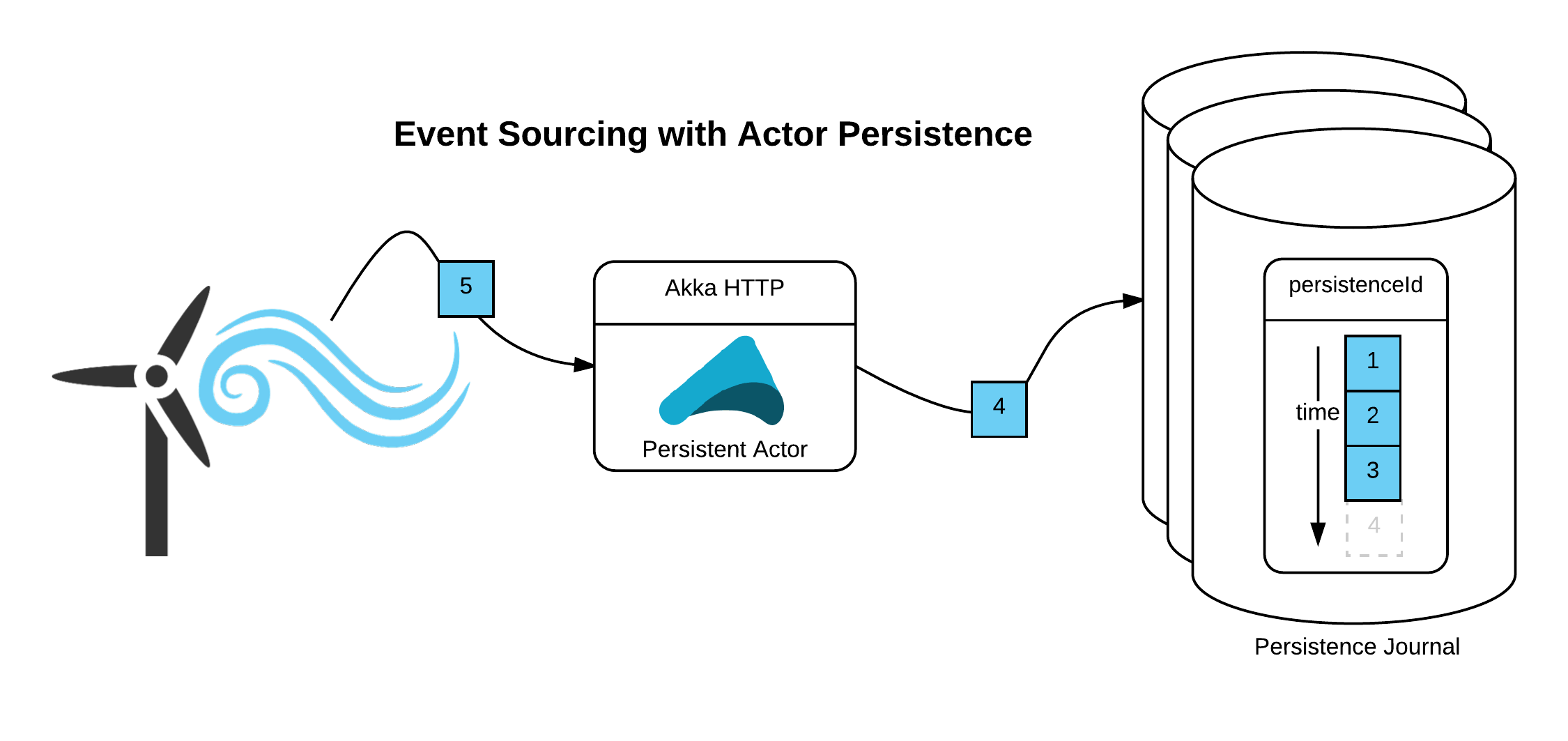
The receiveRecover method is normally used to recover the internal state of the actor by replaying events, in order, from the persisted journal, if the actor is restarted. This persistent actor is greatly simplified compared to most of the other examples that you will encounter. The actor does not maintain any internal state and it does not snapshot the Event Sourced stream. Since the actor has no internal state, the receiveRecover method does nothing. This actor simply records the sequence of events that make up the diagnostic event in the journal. I will return to a more complete example of actor persistence later in this article, but for now, I just want to focus on the streaming aspects.
Streaming Persisted Events
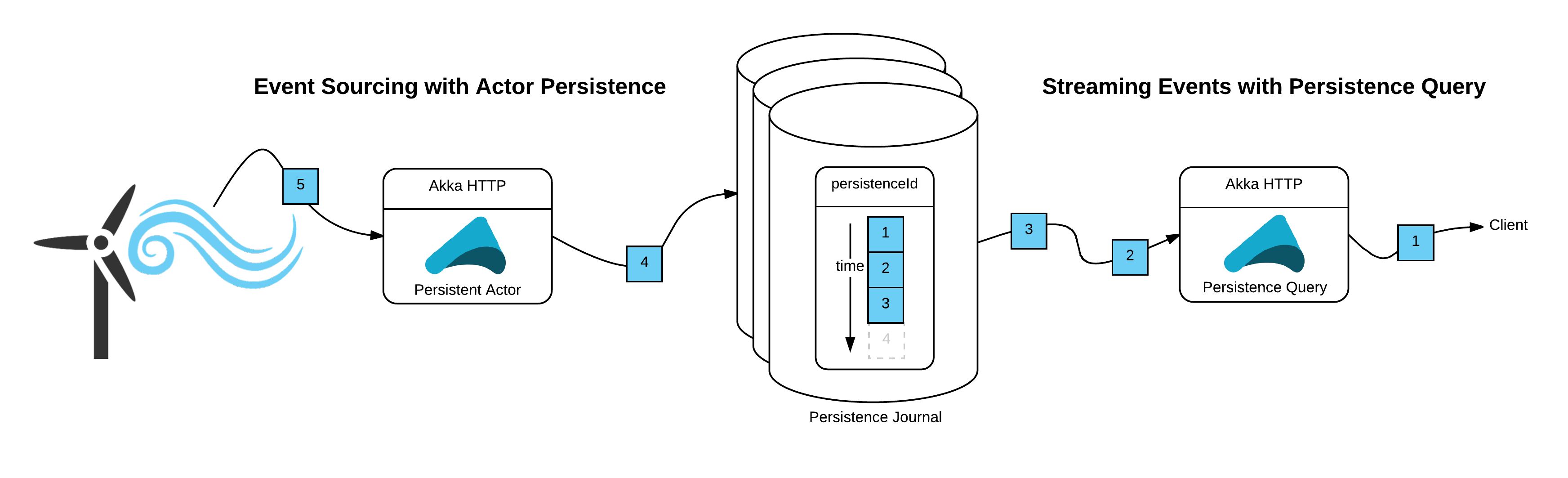
As the events for a particular diagnostic event are committed to the journal by the persistent actor, the Akka Streams API can be used to stream the events. The only thing that is required to stream the events from the journal is the stable persistence identifier. This ends up providing location transparency, something normally associated with actors, to the Akka Streams API. Since the journal is independent from the persistent actor that populates it, it can be referenced by other services that have no knowledge of the actor that persisted the events (or even where, or if, the actor is currently running).
Using Akka Persistence Query, there are two ways that the persisted events can be streamed with the Akka Streams API. The first is using currentEventsByPersistenceId, which will stream all of the events in the journal up to the time of the query, then complete the stream. Events stored after the query time are not included in the result set. This can be used to stream all of the events up to the current time.
val queries = PersistenceQuery(system) .readJournalFor[LeveldbReadJournal](LeveldbReadJournal.Identifier) val persistenceId = "123e4567-e89b-12d3-a456-426655440000" queries.currentEventsByPersistenceId(persistenceId, 0L, Long.MaxValue) .map(_.event) .runWith(Sink.foreach(println))
This technique can be leveraged from Akka HTTP to query all of the events for a particular diagnostic event.
val eventsRoute =
path("events" / uuidRegex) { persistenceId =>
onSuccess {
queries.currentEventsByPersistenceId(persistenceId, 0L, Long.MaxValue)
.map(_.event)
.runWith(Sink.seq)
.mapTo[Seq[Event]]
} { events =>
complete(events)
}
}
The second method is eventsByPersistenceId, which will stream all events up to the query time, but it will keep the stream alive, continuing to stream new events as they are appended to the journal. This is normally accomplished by polling the journal on a configurable interval. The API is identical to currentEventsByPersistenceId.
val queries = PersistenceQuery(system) .readJournalFor[LeveldbReadJournal](LeveldbReadJournal.Identifier) val persistenceId = "123e4567-e89b-12d3-a456-426655440000" queries.eventsByPersistenceId(persistenceId, 0L, Long.MaxValue) .map(_.event) .runWith(Sink.foreach(println))
This method can be used to stream events, in near real-time, to a file, an actor, or another service. As an example, the eventsByPersistenceId can be used to stream events to a WebSocket client, using Akka HTTP and the Akka Streams API.
val eventStreamWebSocket = (persistenceId: String) =>
Flow[Message]
.collect {
case TextMessage.Streamed(textStream) =>
textStream.runWith(Sink.ignore)
Nil
}
.merge(
queries.eventsByPersistenceId(persistenceId, 0L, Long.MaxValue)
.map(_.event),
eagerComplete = true
)
.map(event => TextMessage(event.toString))
val eventStreamRoute =
path("event-stream" / uuidRegex) { persistenceId =>
get {
handleWebSocketMessages(eventStreamWebSocket(persistenceId))
}
}
Streaming events in this manner leverages all of the advantages of the Akka Streams API: flow control, bounded resource usage, and a rich API for expressing streaming workloads. If the downstream is temporarily slower than the upstream, or even unavailable, the stream will backpressure, while the events remain durably persisted in the journal.
The examples above query the entire stream from beginning to end, using the sequence numbers 0L to Long.MaxValue. Rather than streaming all of the events, events can be streamed incrementally, by allowing the client to specify a sequence number from which to begin the query. For example, the events HTTP route above could be modified to allow the client to pass an optional bookmark parameter, representing the sequence number at which to start the query. The response could include an updated bookmark, for the client to use on a subsequent query.
val bookmarkedEventsRoute =
path("events" / uuidRegex) { persistenceId =>
get {
parameters('bookmark.as[Long] ? 0L) { bookmark =>
onSuccess {
queries.currentEventsByPersistenceId(persistenceId, bookmark, Long.MaxValue)
.runWith(Sink.seq)
.mapTo[Seq[EventEnvelope]]
} { envelopes =>
if (envelopes.isEmpty) {
complete(StatusCodes.NoContent)
}
else {
val bookmark = envelopes.last.sequenceNr + 1
val events = envelopes.map(_.event.asInstanceOf[Event])
complete(EventsWithBookmark(bookmark, events))
}
}
}
}
}
Persisting and Querying Snapshots
Most persistent actors maintain internal state. To complete the example, consider that the persistent actor representing the diagnostic event computes key performance indicators, updating them each time an event message is received. The key performance indicators are represented by the Stats class and are left to the imagination of the reader. The persistent actor snapshots the Stats class before stopping, so that it does not need to replay all of the events in order to construct the aggregate statistics for the diagnostic event.
class DiagnosticEvent(id: String) extends PersistentActor {
override def persistenceId: String = id
var stats = Stats()
def updateState(event: Event): Unit = {
stats = stats.update(event)
}
override val receiveRecover: Receive = {
case event: Event => updateState(event)
case SnapshotOffer(_, snapshot: Stats) =>
stats = snapshot
}
override val receiveCommand: Receive = {
case event: Event =>
persist(event) { event =>
updateState(event)
sender() ! Done
}
case QueryStats =>
sender() ! stats
case Stop =>
saveSnapshot(stats)
context.stop(self)
}
}
As an example for how the aggregate statistics can be queried, consider that following HTTP route that uses actor selection to look up the actor reference and then send it a QueryStats message.
val statsRoute =
path("stats" / uuidRegex) { persistenceId =>
get {
onSuccess {
val ref = system.actorSelection(s"/user/$persistenceId")
import akka.pattern.ask
implicit val askTimeout = Timeout(30 seconds)
(ref ? QueryStats).mapTo[Stats]
} { stats =>
complete(stats)
}
}
}
To provide a location-transparent query that can be scaled out on nodes in a cluster, Actor Persistence could be combined with Cluster Sharding, a technique presented in the previous article in this series.
Summary
The traditional roles of actors and streams have been somewhat blurred in this article. Actors typically maintain mutable state and provide an asynchronous query interface with location transparency, whereas streams typically provide flow control and rich semantics for streaming workloads. In this article, however, a persistent actor was responsible for handling a stream of events, appending them to a durable journal using the Event Sourcing model. The Akka Streams API, on the other hand, was used to query the persisted events in a location transparent manner.
This four-part series has focused on how to integrate Akka Actors with the Akka Streams API. I often find that once people understand the power of the Akka Streams API, they can be somewhat confused as to how it should be used in conjunction with Akka Actors. I have provided basic examples for how to interface the Akka Streams API with Akka Actors, in addition to more sophisticated examples demonstrating how Akka Actors can be used to manage the life-cycle of streams, distribute streaming-workloads in an Akka cluster, and provide location-transparency for streams.
The common theme throughout this series is that actors are effective for encapsulating and managing mutable state, providing life-cycle management, fault-tolerance, and distributing workloads in a cluster in a scalable and location-transparent manner. The Akka Streams API is great for providing high-level semantics for streaming data and doing so with asynchronous backpressure, to provide bounded resource constraints. Combined, Akka Actors and the Akka Streams API are complementary and provide an extremely powerful tool-set for building robust, reliable, and scalable distributed-systems for streaming data.
I hope that you found this series valuable. Happy hAkking!